
How can I use natural language in my modeling process to achieve high-quality information models?
The answer to your question is Fact-Oriented Modeling (FOM). This is a family of conceptual methods in which facts are modeled precisely as relationships with an arbitrary number of arguments. This type of modeling makes it easier to understand the model, because natural language is used to create the data model. That's what makes FOM fundamentally different from all other modeling methods. This approach sounds new and exciting. However, its basic features date back to the 1970s.
A mature modeling methodology and suitable tool support have existed for around twenty years. The first implementations with FOM are currently being developed in Germany. But how does this modeling method work and what advantages does it offer for the core layer in a data warehouse project?
Michael Müller, head of data management at the fictitious company FastChangeCo [TED24], heard the following about Fact-Oriented Modeling at the TDWI Roundtable in Frankfurt [TED17b]:
FOM is an approach to modeling information and developing information systems designed to promote model correctness, clarity, and adaptability.
Facts and relationships are written precisely and in natural language so that employees from all departments can easily understand the models and check them for their specific requirements.
Fact-Oriented Modeling
In this article we use an example to demonstrate how FOM can be used to expand the data warehouse in order to manage dual students in the company and to utilize its advantages.
The data warehouse at FastChangeCo is subject to an ongoing development process in order to incorporate new processes or to be able to reflect changes. A model-based approach is used to create the data warehouse and all necessary data marts so that the resulting increase in complexity remains manageable and as many adjustments as possible can be carried out automatically. According to former experiences of FastChangeCo, missing methodical knowledge results in erroneous validation of the created models by the domain experts. One solution to this communication problem is modeling in easily understandable language and structure.
Fact-oriented modeling is a family of conceptual methods that addresses this idea. Under this approach, facts are modeled as relationships with any number of participating objects. This type of modeling makes it easier to understand the model as it is written in a natural language. As a result, the team of modelers at FastChangeCo can communicate much more easily with the domain expert about the model and thus check it together for business-specific requirements.
Before implementing a database or data architecture for an application, FastChangeCo typically creates a conceptual model, independent of the database technology used or the operating processes. The model only covers the part of reality that is relevant to the current scope of the project. This part is referred to in the literature and hereinafter as the Universe of Discourse (UoD).
The goal of the FOM methods is a redundancy-free model at the conceptual level that correctly depicts the facts within a domain. However, the methods go one step further and define algorithms for automatic transformation into other model types, such as a relational model according to Codd or a data vault model. In this way, the development of physical data models for the core data warehouse can be facilitated through generating. Afterwards the modeller needs to focus on the physical optimization of the data models, such as a 3NF or data vault.
From the conceptual to the physical data model
A conceptual model is detached from logical or physical models. At the conceptual level, developed models represent the structure of a domain. They are intended to facilitate communication and the exchange of knowledge between modelers and domain experts. Models that initially only represent the most important factor of the business area are also possible here.
At the logical level, models describe and visualize abstract data structures, for example key constraints are added here or hierarchies are formed.
The concrete implementation takes place at the physical level. The implementation of the logical structure follows the definition of the relevant programming language, after choosing the specific database management system(DBMS).
One fact at a time
To create a high-quality model, the modeler needs an deep understanding of the area to be modeled. Often these are the relevant business objects and processes. The greatest challenge lies in a clear and precise description [Hal95]. In addition, errors in modeling at this stage are particularly serious, as they will affect all further stages of development. Refactoring due to fundamental errors in a data model is both time-consuming and cost-intensive. The later an error is discovered, the more expensive it is to fix it in the data warehouse [Hal95].
The models for an application are typically not created by the domain expert or the subsequent users. It therefore makes sense for the modeler to be able to exchange information with the domain expert about the mapped objects and processes.
“Since people naturally communicate using words, pictures and examples, the best way to describe the UoD clearly and precisely is with natural language, intuitive diagrams and examples” [Hal95]. To support this, information should be examined in the smallest possible unit: “One fact at a time” [Hal95].
According to [ZEH15], the most important features of fact-oriented methods are:
- Instead of general descriptions, verbalizations of concrete fact examples are used as the basis for modeling.
- A procedure is used to show the modeler how to model instead of what to model.
- When modeling, the focus is placed on elementary facts instead of attributes (half facts) or entities (collection of facts).
By using concrete examples, the meaning of the modeled information becomes much clearer than with general descriptions [ZEH15]. The fact examples also serve as the elementary basis for communication between the modeler and the domain expert as well as a decision-making aid for the definition of identifiers or constraints. This feature gives the method family its name fact-oriented. The modeling procedure serves as a step-by-step guide for the modeler on how to reflect the example facts in a conceptual model. This is a clear advantage over methods that only define the syntax, semantics and graphical notation of the model elements [ZEH15]. An elementary fact is a single complete fact that represents the smallest unit of information. The step-by-step modeling of elementary facts is much easier and less error-prone than the complex modeling of a group of facts [ZEH15].
Historical classification
The idea behind FOM came from Nijssen in the 1970s. He worked in a leading position together with a project team to create a new modeling method and published the first results in 1974/1975. In the further course of development, this became the Natural Language Information Analysis Method (NIAM).
Since 2000, all of today's methods in the FOM family have evolved from the NIAM method: Cognition-Enhanced Niam (CogNiam) by Nijssen and Le Cat [NiC09], Second Generation Object-Role Modeling (ORM2) by Halpin [Hal05] and Fully Communication-Oriented Information Modeling (FCO-IM) by Bakema, Zwart and van der Lek [BZL00]. A complete review of the history and the sometimes contradictory developments can be found here [TED17a]: Fact-Oriented Modeling (FOM) - Family, History and Differences.
The idea for FOM and the modeling methods have already existed for some time. Due to the low level of awareness in Germany, the advantages of fact-based modeling have not yet been exploited. In the Netherlands, however, these methods are already being used very successfully in practical projects.
Differentiation of ORM to ERM and UML
Another type of modeling at a conceptual level prior to the evolution of ORM was Entity Relationship Modeling (ERM). Here, the UoD is described by entities that have attributes and can be related to each other. In comparison to this, ORM considers every piece of information in the UoD as an object that plays a role in one or more facts (“objects playing roles”). One advantage of ORM over ERM is that ORM forces the modeler to define each relevant relationship and restriction of an object separately and unambiguously in natural language in the model. This enables a better understanding of the relationships than in the ER model [Hal01].
Both modeling methods include a process for creating the model and a precisely defined graphical notation. However, the focus of ORM compared to ERM is on a step-by-step process based on natural language to make the model easier to understand. An ER model is less suitable for defining, transforming and extending a conceptual model if the domain expert needs to validate the model himself [Hal95].
Another conceptual method from the field of object orientation is the Unified Modeling Language (UML). This language contains many different types of diagrams, divided into structural and behavioral diagrams. The non-standardized notation and an overly formal and therefore unnatural verbalization are also critical aspects of this method: UML has no standard notation for clear key identification. The user can also define their own constraints in the model. These two points make portability more difficult [Hal01]. Since the roles of a relation have no order in UML, a verbalization can have several interpretations and thus lead to misunderstandings or errors in the implementation [Hal01]. In ORM, these disadvantages are eliminated by a standardized technique for the verbalization of facts and a clear graphical notation in this regard.
Spoilt for choice: FCO-IM or ORM2
FastChangeCo would like to use FOM for conceptual modeling in its data warehouse projects in the future. However, the data modeling team at FastChangeCo must first choose on one of the methods from the FOM family. ORM2 and FCO-IM are on the shortlist.
The different goals of the individual methods are already reflected in their names: Second Generation Object Role Modeling (ORM2) aims to model objects that play a role in various facts. Fully Communication-Oriented Information Modeling (FCO-IM) aims to model only the information that is communicated (the exact modeling steps and explanations of the most important constraints in ORM2 and FCO-IM are explained in [TED17a]).
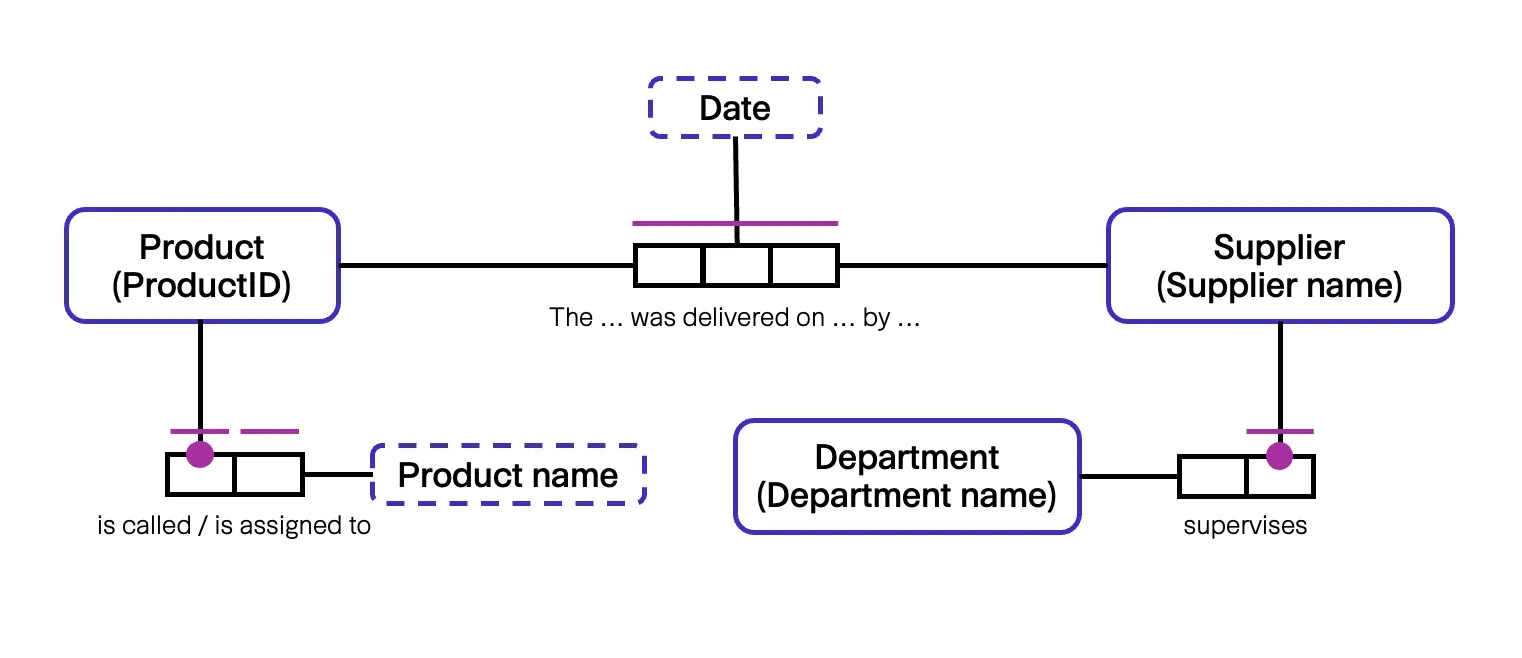
Example Model ORM2
This difference results in a different view on the facts: ORM2 explicitly distinguishes between Object Type and Fact Type, whereas FCO-IM considers Object Types to be simply a kind of Fact Types. The advantage of this distinction in ORM2 is a clearly recognizable distinction in the notation. The advantage of FCOIM, on the other hand, is that all facts can be treated uniformly. As a result fewer concepts are required in the metamodel and the transformation process is easier to perform.
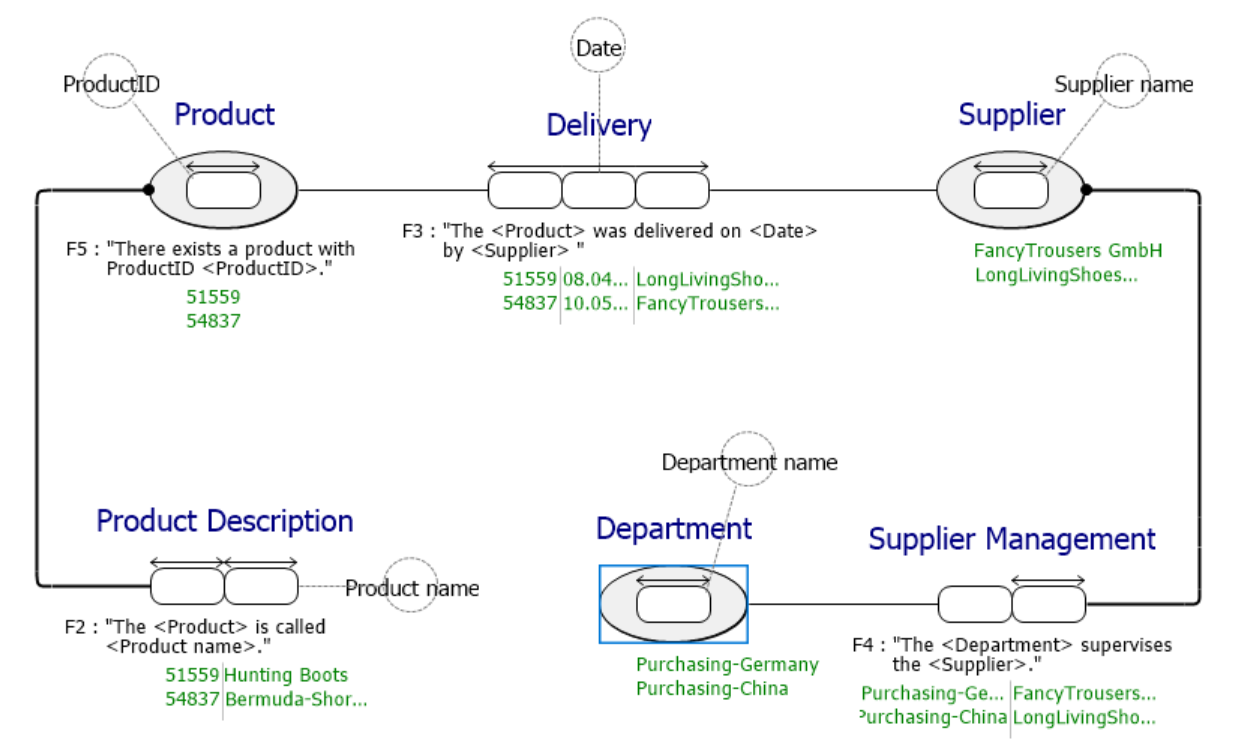
Example Model FCO-IM
The biggest difference in the model notation is the additional textual annotation of the model elements. By default, in FCO-IM each constraint is annotated with its ID and each connection with the corresponding unique identifier of the object type. Example populations are also displayed in the model. In ORM2, only a few textual annotations are provided as standard; these are used for additional constraints or derivation rules. The populations of the object or fact types are also not included in the graphical notation and must be added manually using text fields.
In ORM2, there is a clear color separation of elements compared to FCO-IM: All constraints and subtypes are purple, all object types are blue and all connections and fact types are black. This makes the model elements stand out more clearly from one another. The fact expressions in FCO-IM and the textual annotation on the fact type in ORM2 make it easy to read the model in both cases by linking the roles with the referenced fact or object types.
ORM2 and FCO-IM both follow the characteristics of Fact-Oriented Modeling: They use verbalizations of concrete fact examples, have a design process as a guide and model elementary facts. The design process differs only slightly, as both follow the original structure of the NIAM Conceptual Schema Design Procedure (CSDP).
The model elements are also very similar, although in ORM2 significantly more expressive constraints can be mapped in the model. In an FCO-IM model, on the other hand, more textual annotations of the elements and the addition of an example population are provided in the standard notation.
The modeling process is defined very similar in both methods: First, concrete example data for the business area to be modeled must be collected and verbalized in the language of the domain expert. The modeler then analyzes these sentences based on their components and uses them to form individual fact types. The analysis results in an initial basic structure of all important elements and their relationships to each other. This structure is then expanded step by step to include many different constraints.
Tool support is available for both methods.The best tools are NORMA for ORM2 and CaseTalk for FCO-IM. (There are others, but they either have a very limited range of functions, are not very user-friendly or are no longer maintained). With both tools, all constraints of the methods can be mapped in a model.
The tool CaseTalk also has the option of carrying out the analysis step of the FCO-IM procedure with the software. This reduces the modeler's manual workload. NORMA does not provide this support; the modeler has to define all object and fact types in advance. In a large model, this creates the risk of redundant modeling. This is prevented in CaseTalk, because facts that have already been analyzed are matched together in the model repository.
Both tools enable transformation into a redundancy-free relational schema. However, so far only simple constraints can be converted, as a transformation of complex constraints is made more difficult by the limited possibilities of the target models on a logical or physical level. The transformation process of an FCO-IM model and its result is much easier to understand than in ORM2.
In the further course of the project, FastChangeCo therefore decided to model its use case with FCO-IM.
FCO-IM in a concrete example
The company FastChangeCo would like to use a new information system to manage its dual students. Previously, this data was managed manually by the human resources department. The new system should reflect the following business rules (small excerpt for showcase):
- A student is uniquely identified with a StudID.
- A student has exactly one first and last name.
- A student studies exactly one degree program.
- A student receives a final grade in each employed department.
Specific sample data for this use case is collected with the help of the domain expert:
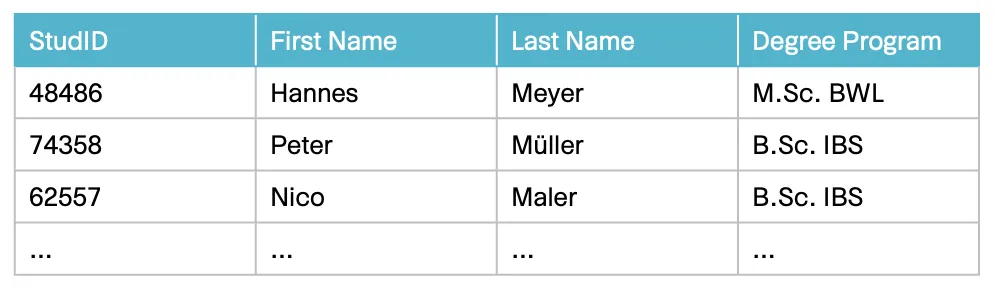
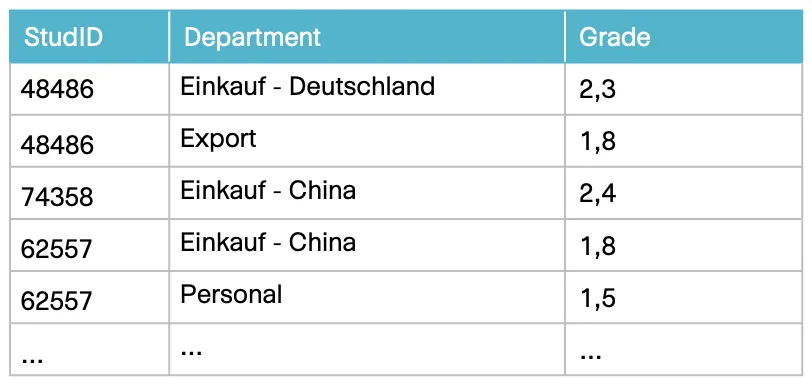
All sample information is initially referred to as facts. In the modeling process the team creates sentences in natural language from the sample data. The sentences that express an elementary fact are referred to as fact expressions. Fact types are created by grouping fact expressions that express facts of the same type. The sentences of the fact expressions that have been sorted into the same group have a similar structure. They have exactly the same number of elements that play a role in the fact.
If a placeholder for any instantiation of the role is placed in the fact expression for each of these roles, the modeler receives a sentence structure in which he can enter suitable data of the linked fact types for the placeholders. These sentence structures form the fact expression types. Furthermore, the elements that play a role in the fact types are divided into object types and label types. All elements that represent a meaningful object ([BZL00]) in the domain are classified as object types, all others as label types. An object type always requires a connection to one or more label types for unique identification.
The domain expert verbalizes the example data shown above. The resulting sentences must be correct and clearly understandable and always express only one elementary fact. For example, the sentence "The student 48486 has the first name Hannes and is studying the degree program M.Sc.BWL." contains two elementary facts:
- The student 48486 has the first name Hannes.
- The student 48486 is studying the degree program M.Sc.BWL.
By sorting and analyzing the sentences, the modeler can form fact types and identify object or label types. An example analysis is shown for the fact type "Department Grade":
Fact Type
Department Grade
Fact Expressions
The student 48486 has achieved a grade of 2.3 in the department Einkauf-Deutschland.
The student 62557 has achieved a grade of 1.8 in the department Einkauf-China.
Fact Expression Type
The <Student> has achieved a grade of <Grade> in the <Department>.
Object Types
Student, Department
Label Types
Grade
The model elements shown in the following are created by analyzing all the sample information. The constraints are then determined using the business rules and added to the model definition.
Fact Types
-
First name of Student
-
Last name of Student
-
Degree Program of Student
-
Department Grade
Object Types
-
Student
-
Department
-
Degree Program
Label Types
-
First Name
-
Last Name
-
Grade
-
StudID
-
Degree Program Name
-
Department Name
Casetalk as the FCO-IM supporting tool reduces the developing time by supporting the developer in the analyzation of the records and the definition of constraints. The final FCO-IM model for FastChangeCo's use case:
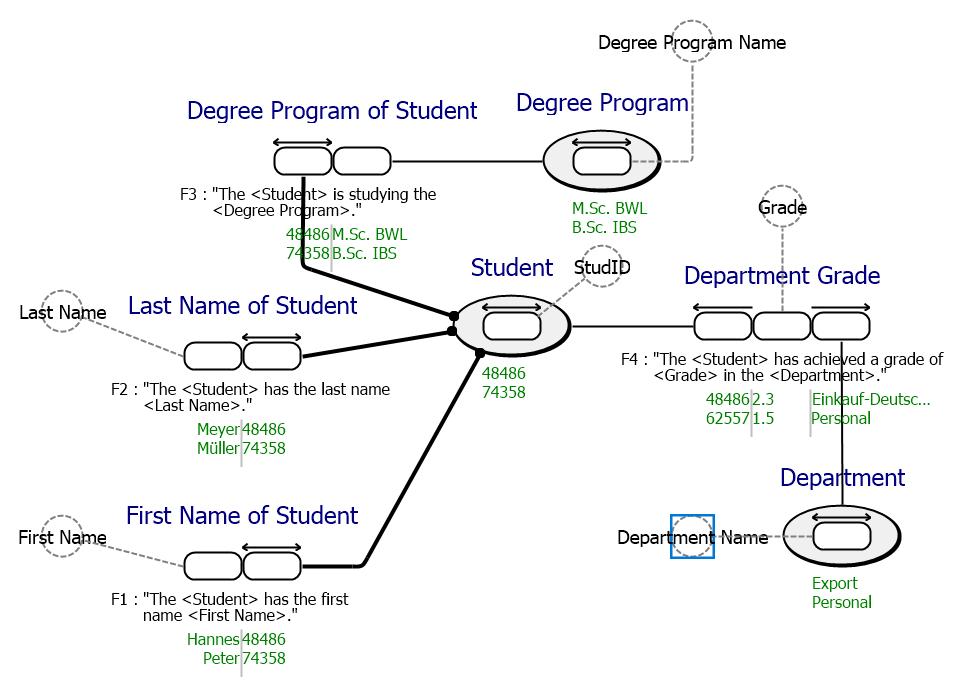
CaseTalk automatically creates a verbalized documentation for the model. This allows the domain expert to validate the model even without understanding the graphical notation.
The modeler can use CaseTalk to convert this FCO-IM model into a relational schema by using the GLR transformation and then directly generate DDL code to implement a database structure in the core data warehouse.
Conclusion
The FCO-IM method provides FastChangeCo with a high-quality automatically generated documentation in natural language, which the domain expert can validate independently. Only relevant elements of the business area are modeled by using concrete example information.
The conceptual model can then be transformed automatically into a redundancy-free physical relational data model for FastChangeCo's core data warehouse and implemented in a database system. The sample data can be transferred directly into the new system for testing purposes. Thanks to the clear and precisely defined modeling process in FCO-IM, the model can be extended with additional information at any time. These extensions can in turn be transformed and implemented directly. This allows FastChangeCo to make communication between data modelers and domain experts about information and the model much easier and more effective. By validating concrete examples in natural language, FastChangeCo creates better conceptual models and subsequently better physical data models with high data quality.
With the growing spread of Fact-Oriented Modeling, the methods presented in this article have good prospects of being increasingly used in projects. In addition, all the methods presented are being further developed (see [Hal15; ZEH15]).
Literature
[BJR96] Booch, G. / Jacobson, I. / Rumbaugh, J.: The unified modeling language. Unix Review, 14. Jg., Nr. 13, 1996, S. 5
[BZL00] Bakema, G. / Zwart, J. P. / van der Lek, H.: Fully communication-oriented information modelling. Ten Hagen Stam 2000
[Che76] Chen, P. P. S.: The entity-relationship model – toward a unified view of data. ACM Transactions on Database Systems (TODS), 1(1),1976, S. 9–36
[Cod70] Codd, E. F.: A relational model of data for large shared data banks. Communications of the ACM, 13(6), 1970, S. 377–387
[Fal76] Falkenberg, E. D.: Concepts for modelling information. In: Proc. IFIP TC2/WG2.6, Working Conference on Modelling in Data Base Management Systems, 1976, S. 95–109
[Hal95] Halpin, T.: Conceptual schema and relational database design. 2. Aufl., Prentice Hall 1995
[Hal01] Halpin, T.: Information Modeling and Relational Databases: From Conceptual Analysis to Logical Design. Morgan Kaufmann 2001
[Hal05] Halpin, T.: ORM 2. In: OTM Confederated International Conferences: On the Move to Meaningful Internet Systems. Springer 2005, S. 676–687
[Hal15] Halpin, T.: Object-Role Modeling Fundamentals: A Practical Guide to Data Modeling with ORM. Technics Publications 2015
[NiC09] Nijssen, G. M. / Le Cat, A.: Kennis Gebaseerd Werken: de manier om kennis productief te Maken. PNA Publishing 2009
[TED24] Lerner, D.: FastChangeCo – A Fictitious Company. https://tedamoh.com/en/academy/fastchangeco, abgerufen am 12.6.2017
[TED17a] Lerner, D. / Volkmann, S.: Fact-Oriented Modeling (FOM) – Family, History and Differences. https://tedamoh.com/en/blog/data-modeling/53-fom/92-fact-oriented-modeling-fom-family-history-and-differences, abgerufen am 26.6.2017
[TED17b] Lerner, D.: Sketch Notes Reflections at TDWI Roundtable with FCO-IM. 30.1.2017, https://tedamoh.com/en/blog/48-tdwi-roundtable/85-sketch-notes-reflections-at-tdwi-roundtable-with-fco-im, abgerufen am 28.4.2017
[ZEH15] Zwart, J. P. / Engelbart, M. / Hoppenbrouwers, S.: Fact Oriented Modeling with FCO-IM: Capturing Business Semantics in Data Models with Fully Communication Oriented Information Modeling. Technics Publications 2015