
Wie kann ich natürliche Sprache in meinem Modellierungsprozess verwenden, um qualitativ hochwertige Informationsmodelle zu erstellen?
Die Antwort auf Ihre Frage lautet faktenorientierte Modellierung (Fact-Oriented Modeling, FOM). Dies ist eine Familie von konzeptuellen Methoden, bei denen die Fakten präzise als Beziehungen mit beliebig vielen Argumenten modelliert werden. Diese Art der Modellierung ermöglicht ein einfacheres Verständnis des Modells, da zur Erstellung des Datenmodells natürliche Sprache verwendet wird. Dies unterscheidet FOM auch grundlegend von allen anderen Modellierungsmethoden. Dieser Ansatz hört sich neu und spannend an. Er geht jedoch in Grundzügen bereits in die 1970er-Jahre des vorigen Jahrhunderts zurück.
Eine ausgereifte Methodik zur Modellierung sowie eine geeignete Tool-Unterstützung existieren seit rund zehn Jahren. Erste Umsetzungen mit FOM entstehen zurzeit in Deutschland. Doch wie funktioniert diese Modellierungsmethode und welche Vorteile ergeben sich daraus für den Core Layer in einem Data-Warehouse-Projekt?
Michael Müller, Head of Data Management in dem fiktiven Unternehmen FastChangeCo [TED24], hat auf dem TDWI Roundtable in Frankfurt Folgendes über Fact-Oriented Modeling gehört [TED17b]:
FOM ist ein Ansatz zur Modellierung von Informationen und Entwicklung von Informationssystemen, der die Korrektheit, Klarheit und Anpassbarkeit der Modelle fördern soll.
Fakten und Beziehungen werden präzise und in natürlicher Sprache verfasst, sodass Mitarbeiter aus allen Fachbereichen die Modelle gut verstehen können und sie auf ihre fachspezifischen Anforderungen überprüfen können.
Fact-Oriented Modeling
Anhand eines Beispiels zeigt dieser Artikel, wie FOM für die Erweiterung des Data Warehouse zur Betreuung der dualen Studenten im Unternehmen eingesetzt und dessen Vorteile genutzt werden können.
Das Data Warehouse bei FastChangeCo unterliegt einer ständigen Weiterentwicklung, um neue Prozesse aufzunehmen oder Änderungen abbilden zu können. Damit die dadurch zunehmende Komplexität beherrschbar bleibt und möglichst viele Anpassungen automatisch durchgeführt werden können, wird ein modellbasierter Ansatz zur Erstellung des Data Warehouse bzw. aller notwendigen Data Marts genutzt.
Nach den bisherigen Erfahrungen von FastChangeCo führt fehlendes methodisches Wissen zu einer fehlerhaften Validierung der erstellten Modelle durch die Fachexperten. Ein Lösungsansatz für dieses Kommunikationsproblem ist die Modellierung in leicht verständlicher Sprache und Struktur.
Fact-Oriented Modeling ist eine Familie von konzeptuellen Methoden, die sich dieser Idee angenommen haben. Hier werden Fakten als Beziehungen mit beliebig vielen teilnehmenden Objekten modelliert. Die Art der Modellierung ermöglicht ein einfacheres Verständnis des Modells, da es in einer natürlichen Sprache gehalten wird. Dadurch kann das Team der Modellierer bei FastChangeCo erheblich leichter mit dem Domänenexperten über das Modell kommunizieren und es somit gemeinsam auf fachspezifische Anforderungen überprüfen.
Vor der Implementierung einer Datenbank oder einer Datenarchitektur für eine Anwendung wird bei FastChangeCo typischerweise ein konzeptuelles Modell, unabhängig von der eingesetzten Datenbanktechnologie oder den Bewirtschaftungsprozessen, erstellt. Das Modell bildet dabei nur den Teil der Realität ab, der für den aktuellen Scope des Projekts relevant ist. Dieser Teil wird in der Literatur und im Folgenden als Universe of Discourse (UoD) bezeichnet.
Das Ziel der FOM-Methoden ist ein redundanzfreies Modell auf der konzeptuellen Ebene, das die Fakten innerhalb einer Domäne korrekt abbildet. Die Methoden gehen jedoch noch einen Schritt weiter und definieren Algorithmen zur automatischen Transformation in andere Modellarten, wie zum Beispiel in ein relationales Modell nach Codd oder auch in ein Data-Vault-Modell. So kann die Entwicklung von physischen Datenmodellen für das Core Data Warehouse durch die Generierung erleichtert werden. Im Anschluss an die Generierung kann und muss sich der Modellierer auf die physische Optimierung der Datenmodelle, wie zum Beispiel eines 3NF oder Data Vault, konzentrieren.
Vom konzeptionellen zum physischen Datenmodell
Ein konzeptuelles Modell ist zunächst von logischen oder physischen Modellen losgelöst. Auf der konzeptuellen Ebene werden Modelle zur Darstellung der Struktur einer Domäne entwickelt. Sie sollen der Kommunikation und dem Wissensaustausch zwischen Modellierer und Domänenexperte dienen. Möglich sind hierbei auch Modelle, die zunächst nur den wichtigsten Faktor des Geschäftsbereichs abbilden.
In der logischen Ebene werden Modelle bereits in Form von abstrakten Datenstrukturen beschrieben, beispielsweise werden hier Schlüssel-Constraints hinzugefügt oder Hierarchien gebildet.
Auf der physischen Ebene findet die konkrete Implementierung statt. Es wird ein spezifisches Datenbankmanagementsystem (DBMS) gewählt, die Programmiersprache festgelegt und die logische Struktur implementiert.
One fact at a time
Um ein Modell mit hoher Qualität zu erstellen, benötigt der Modellierer ein tiefgreifendes Verständnis des zu modellierenden Bereichs. Oft sind dies die relevanten Geschäftsobjekte und -prozesse. Die größte Herausforderung liegt in einer klaren und präzisen Beschreibung [Hal95]. Außerdem sind Fehler bei der Modellierung zu diesem Zeitpunkt besonders schwerwiegend, da sich diese durch alle weiteren Stufen der Entwicklung ziehen. Ein Refactoring aufgrund elementarer Fehler in einem Datenmodell ist sowohl zeit- als auch kostenintensiv. Je später ein Fehler entdeckt wird, desto kostspieliger ist seine Behebung im Data Warehouse [Hal95].
Die Modelle für eine Anwendung werden typischerweise nicht vom Domänenexperten bzw. den späteren Anwendern erstellt. Daher ist es sinnvoll, wenn der Modellierer sich mit dem Domänenexperten über die abzubildenden Objekte und Prozesse austauschen kann: „Da Menschen natürlicherweise über Worte, Bilder und Beispiele kommunizieren, ist der beste Weg, den UoD klar und präzise zu beschreiben, mit natürlicher Sprache, intuitiven Diagrammen und Beispielen“ [Hal95]. Zur Unterstützung soll eine Information in der kleinstmöglichen Einheit untersucht werden: „One fact at a time“ [Hal95].
Die wichtigsten Merkmale der faktenorientierten Methoden sind laut [ZEH15]:
- Statt allgemeiner Beschreibungen werden Verbalisierungen konkreter Faktenbeispiele als Basis zur Modellierung genutzt.
- Es wird ein Verfahren vorgegeben, das dem Modellierer zeigt, wie man modelliert, statt was zu modellieren ist.
- Bei der Modellierung wird der Fokus auf elementare Fakten gelegt statt auf Attribute (halbe Fakten) oder Entitäten (Ansammlung von Fakten).
Durch die Nutzung konkreter Beispiele wird die Bedeutung der modellierten Informationen deutlich klarer als bei generellen Beschreibungen [ZEH15]. Die Faktenbeispiele dienen ebenso als Basis zur Kommunikation zwischen Modellierer und Domänenexperte wie auch zur Entscheidungshilfe bei der Definition von Identifikatoren oder Nebenbedingungen (Constraints). Dieses Merkmal gibt der Methodenfamilie den Namen fact-oriented.
Das Verfahren zur Modellierung dient dem Modellierer als schrittweise Anleitung, wie er die Beispielfakten in einem konzeptuellen Modell abbilden kann. Dies ist ein deutlicher Vorteil gegenüber Methoden, die lediglich die Syntax, Semantik und grafische Notation der Modellelemente definieren [ZEH15].
Ein elementarer Fakt ist ein einzelner vollständiger Fakt, der die kleinste Einheit an Informationen darstellt. Die schrittweise Modellierung elementarer Fakten ist deutlich leichter und weniger fehleranfällig als die komplexe Modellierung einer Gruppe von Fakten [ZEH15].
Historische Einordnung
Die Idee hinter FOM stammt von Nijssen aus den 70er-Jahren des letzten Jahrhunderts. Er arbeitete in leitender Position zusammen mit einem Projektteam daran, eine neue Modellierungsmethode zu erschaffen, und veröffentlichte 1974/1975 erste Ergebnisse. Im weiteren Verlauf der Entwicklung wurde daraus die Natural Language Information Analysis Method (NIAM).
Aus der NIAM-Methode sind seit dem Jahr 2000 alle heutigen Methoden der FOM-Familie entstanden: Cognition-Enhanced Niam (CogNiam) von Nijssen und Le Cat [NiC09], Second Generation Object-Role Modeling (ORM2) von Halpin [Hal05] und Fully Communication-Oriented Information Modeling (FCO-IM) von Bakema, Zwart und van der Lek [BZL00]. Eine vollständige Aufarbeitung der Historie und der teils gegensätzlichen Entwicklungen kann hier [TED17a] nachgelesen werden: Fact-Oriented Modeling (FOM) - Family, History and Differences.
Die Idee zu FOM sowie die Modellierungsmethoden existieren bereits seit längerer Zeit. Aufgrund der geringen Bekanntheit in Deutschland wurden die Vorteile der faktenorientierten Modellierung bisher nicht genutzt. In den Niederlanden hingegen werden diese Methoden bereits sehr erfolgreich in praktischen Projekten eingesetzt.
Abgrenzung von ORM zu ERM und UML
Eine weitere Art der Modellierung auf konzeptueller Ebene war vor der Entstehung des ORM das Entity Relationship Modeling (ERM). Der UoD wird hier durch Entitäten beschrieben, die Attribute besitzen und in Relation zueinander stehen können.Im Gegensatz dazu wird in ORM jede Information des UoD als Objekt angesehen, das in einem oder mehreren Fakten eine Rolle spielt („Objects playing roles“). Ein Vorteil von ORM gegenüber ERM ist, dass ORM den Modellierer zwingt, jede relevante Beziehung und Einschränkung eines Objekts separat und eindeutig in natürlicher Sprache im Modell zu definieren. Dies ermöglicht ein besseres Verständnis der Beziehungen als im ER-Modell [Hal01].
Beide Modellierungsmethoden enthalten einen Prozess zur Erstellung des Modells und eine präzise definierte grafische Notation. Der Fokus bei ORM liegt gegenüber ERM jedoch auf einem Schritt-für-Schritt-Prozess basierend auf natürlicher Sprache, um das Modell verständlicher zu machen. Ein ER-Modell ist weniger geeignet für das Formulieren, Transformieren und Erweitern eines konzeptuellen Modells, wenn der Domänenexperte das Modell selbst validieren soll [Hal95].
Eine weitere konzeptuelle Methode aus dem Bereich der Objektorientierung ist die Unified Modeling Language (UML). Die Sprache enthält viele verschiedene Diagrammtypen, unterteilt in Struktur- und Verhaltensdiagramme. Kritisch an dieser Methode sind auch hier die nicht standardisierte Notation und eine zu formale und somit nicht natürliche Verbalisierung: UML besitzt keine Standardnotation für eine eindeutige Schlüssel-kennzeichnung. Der Benutzer kann zudem eigene Constraints im Modell definieren. Diese beiden Punkte erschweren die Portabilität [Hal01]. Da die Rollen einer Relation in UML keine Ordnung besitzen, kann eine Verbalisierung mehrere Interpretationen haben und somit zu Missverständnissen oder Fehlern in der Implementierung führen [Hal01]. In ORM werden diese Nachteile durch eine standardisierte Technik zur Verbalisierung von Fakten und einer diesbezüglich eindeutigen grafischen Notation aufgehoben.
Qual der Wahl: FCO-IM or ORM2
FastChangeCo möchte zukünftig in ihren DataWarehouse-Projekten die konzeptionelle Modellierung mit FOM durchführen. Zuvor muss sich das Team der Datenmodellierer bei FastChangeCo allerdings für eine der Methoden aus der FOM-Familie entscheiden. In der engeren Auswahl sind dabei ORM2 und FCO-IM.
Die unterschiedlichen Ziele der einzelnen Methoden spiegeln sich bereits in ihren Namen wider: Second Generation Object Role Modeling (ORM2) zielt darauf ab, Objekte zu modellieren, die in verschiedenen Fakten eine Rolle einnehmen. Fully Communication-Oriented Information Modeling (FCO-IM) setzt sich das Ziel, nur diejenigen Informationen zu modellieren, über die auch kommuniziert wird (die genauen Schritte zur Modellierung sowie Erklärungen der wichtigsten Constraints in ORM2 und FCO-IM sind in [TED17] erläutert).
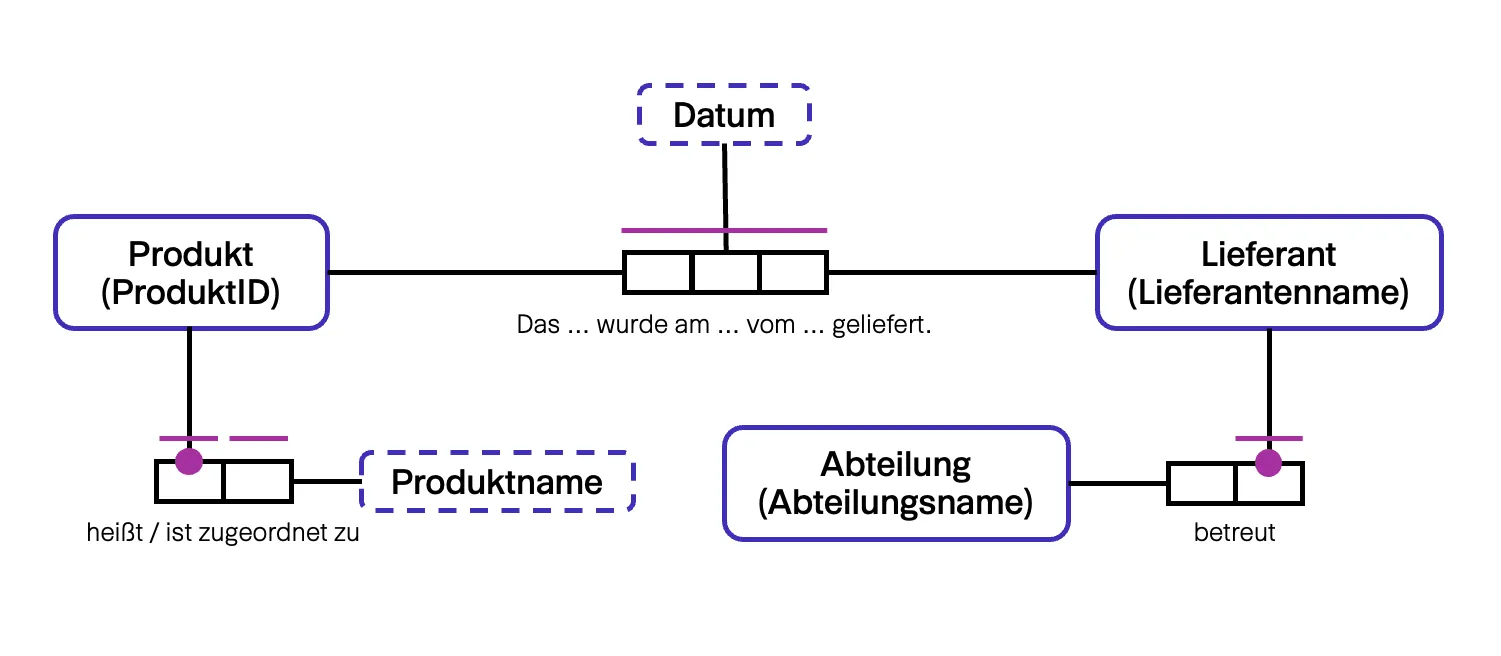
Beispielmodell ORM2
Dieser Unterschied resultiert in einer abweichenden Sichtweise auf die Fakten: ORM2 unterscheidet explizit zwischen Object Type und Fact Type, wohingegen FCO-IM Object Types lediglich als eine Art von Fact Types ansieht. Der Vorteil dieser Unterscheidung in ORM2 ist eine deutlich erkennbare Abgrenzung in der Notation. Der Vorteil des FCO-IM hingegen liegt darin, dass alle Fakten einheitlich behandelt werden können. Somit sind weniger Konzepte im Metamodell nötig und der Transformationsprozess ist einfacher durchzuführen.
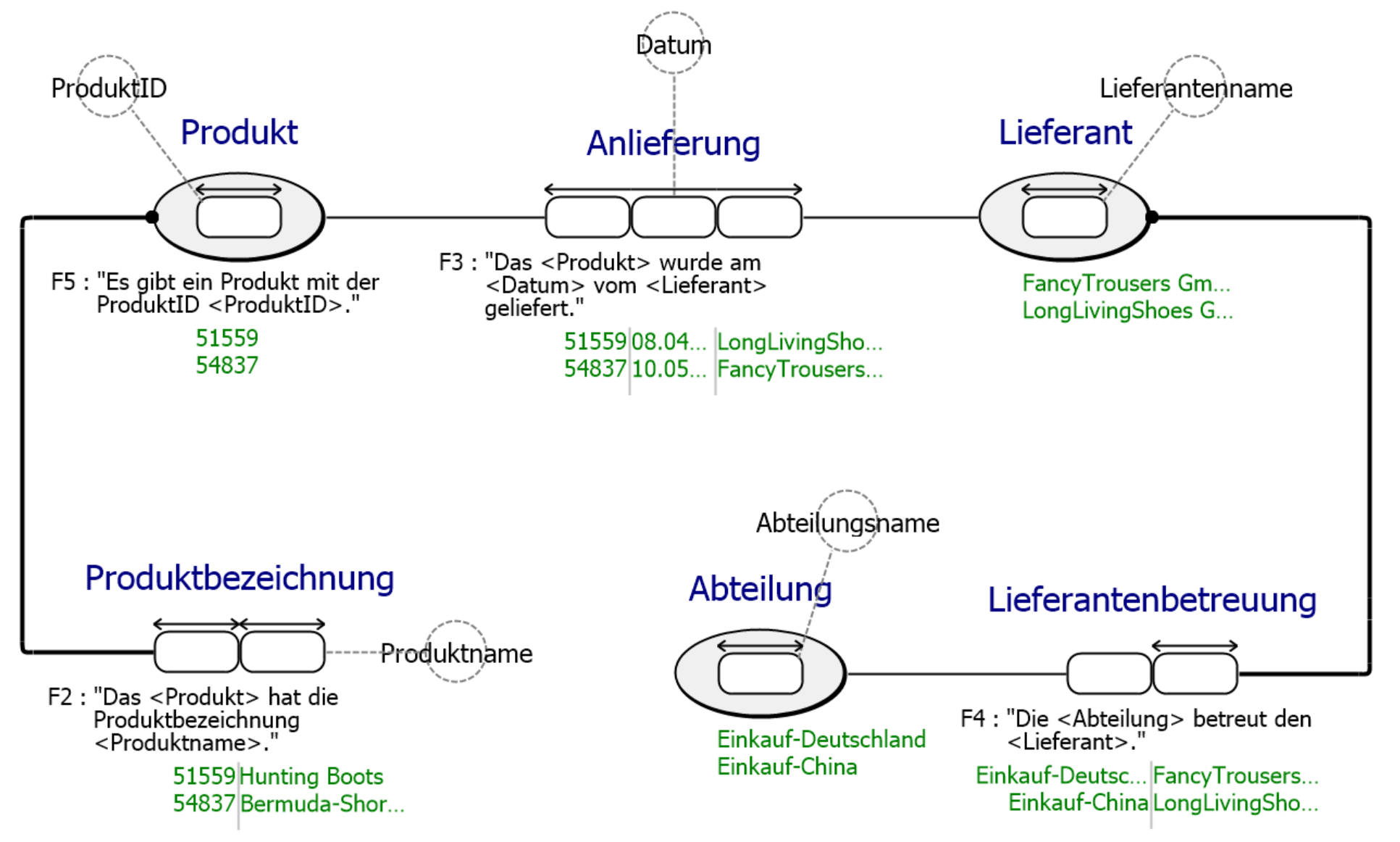
Beispielmodell FCO-IM
Der größte Unterschied in der Modellnotation ist die zusätzliche textuelle Annotation der Modellelemente. In FCO-IM ist standardmäßig an jeder Constraint ihre ID und an jeder Verbindung der zugehörige eindeutige Identifizierer des Object Type vermerkt. Außerdem werden im Modell Beispielpopulationen angezeigt. In ORM2 sind standardmäßig nur wenige textuelle Annotationen vorgesehen, diese dienen für zusätzliche Constraints oder Ableitungsregeln. Auch die Populationen der Object oder Fact Types sind nicht in der grafischen Notation enthalten und müssen manuell durchTextfelder hinzugefügt werden.
In ORM2 gibt es gegenüber FCO-IM eine klare farbliche Trennung von Elementen: Alle Constraints und Subtypes sind violett, alle Object Types sind blau und alle Verbindungen und Fact Types sind schwarz. Dadurch heben sich die Modellelemente deutlicher voneinander ab.Die Fact Expressions in FCO-IM und die textuelle Annotation am Fact Type in ORM2 ermöglichen in beiden Fällen ein einfaches Lesen des Modells durch Verknüpfung der Rollen mit den referenzierten Fact bzw. Object Types.
ORM2 und FCO-IM verfolgen gleichermaßen die Merkmale des Fact-Oriented Modeling: Sie nutzen Verbalisierungen konkreter Beispielfakten, besitzen einen Designprozess als Anleitung und modellieren elementare Fakten. Der Designprozess unterscheidet sich nur leicht voneinander, denn beide verfolgen die ursprüngliche Struktur der NIAM Conceptual Schema Design Procedure (CSDP).
Auch die Modellelemente ähneln sich sehr, wobei in ORM2 deutlich mehr ausdrucksvolle Constraints im Modell abbildbar sind. In einem FCO-IM-Modell sind demgegenüber mehr textuelle Annotationen der Elemente sowie das Anfügen einer Beispielpopulation vorgesehen.
Für beide Methoden gibt es Tool-Unterstützung. Als beste Tools seien hier NORMA für ORM2 und CaseTalk für FCO-IM angeführt. (Es gibt noch weitere, die jedoch entweder einen sehr geringen Funktionsumfang oder eine geringe Benutzerfreundlichkeit haben oder nicht mehr gepflegt werden). Mit beiden Tools sind sämtliche Constraints der Methoden in einem Modell abbildbar.
Das Tool CaseTalk besitzt die Möglichkeit, auch den Analyseschritt der FCO-IM-Procedure mit der Software durchzuführen. Dies nimmt dem Modellierer einen großen manuellen Aufwand ab. In NORMA gibt es diese Unterstützung nicht, der Modellierer muss bereits vorab alle Object und Fact Types festlegen. In einem großen Modell entsteht dadurch die Gefahr, redundant zu modellieren. Dies wird in CaseTalk unterbunden, da bereits analysierte Fakten durch einen Match gefunden und miteinander verknüpft werden.
Beide Tools ermöglichen die Transformation in ein redundanzfreies relationales Schema. Es können bisher jedoch nur einfache Constraints umgewandelt werden, da eine Transformation komplexer Constraints durch die eingeschränkten Möglichkeiten der Zielmodelle auf logischer oder physischer Ebene erschwert wird. Der Transformationsprozess eines FCO-IM-Modells sowie dessen Ergebnis ist deutlich besser zu verstehen als in ORM2.
Im weiteren Verlauf des Projekts hat sich FastChangeCo daher dazu entschlossen, ihren Use Case mit FCO-IM zu modellieren.
FCO-IM im konkreten Beispiel
Die Firma FastChangeCo möchte die Betreuung ihrer dualen Studenten mit einem neuen Informationssystem durchführen. Bisher wurden diese Daten von der Personalabteilung manuell verwaltet. Folgende Geschäftsregeln soll das neue System abbilden:
- Ein Student wird mit einer StudID eindeutig identifiziert.
- Ein Student hat genau einen Vor- und Nachnamen.
- Ein Student studiert genau einen Studiengang.
- In jeder eingesetzten Abteilung erhält ein Student eine Abschlussnote.
Mit Hilfe des Domänenexperten werden konkrete Beispieldaten für diesen Use Case gesammelt:
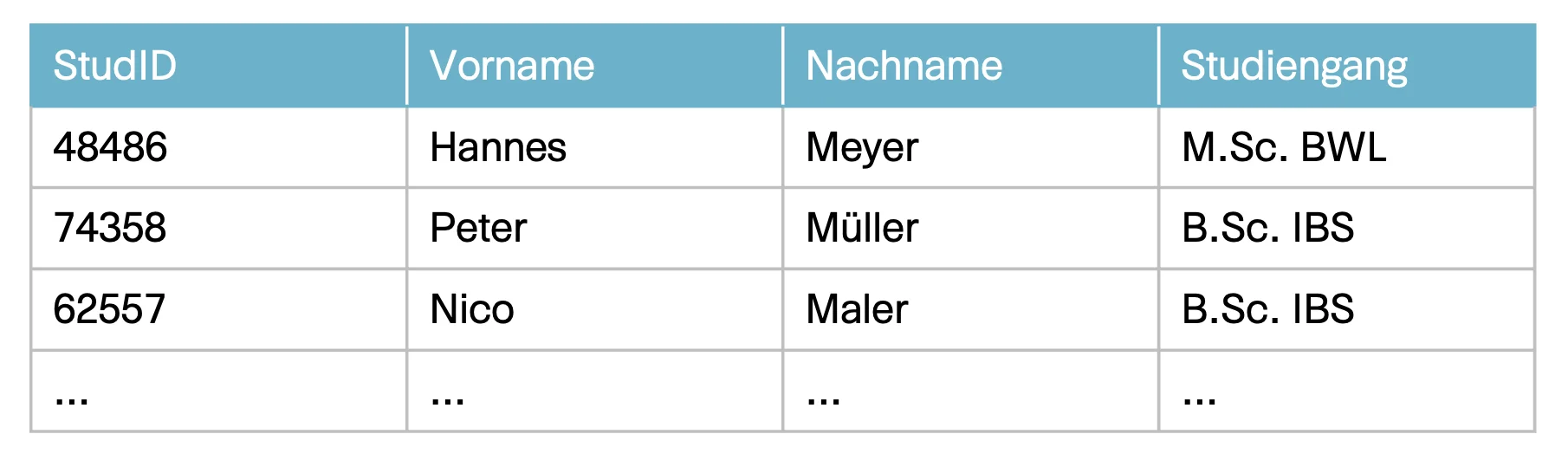
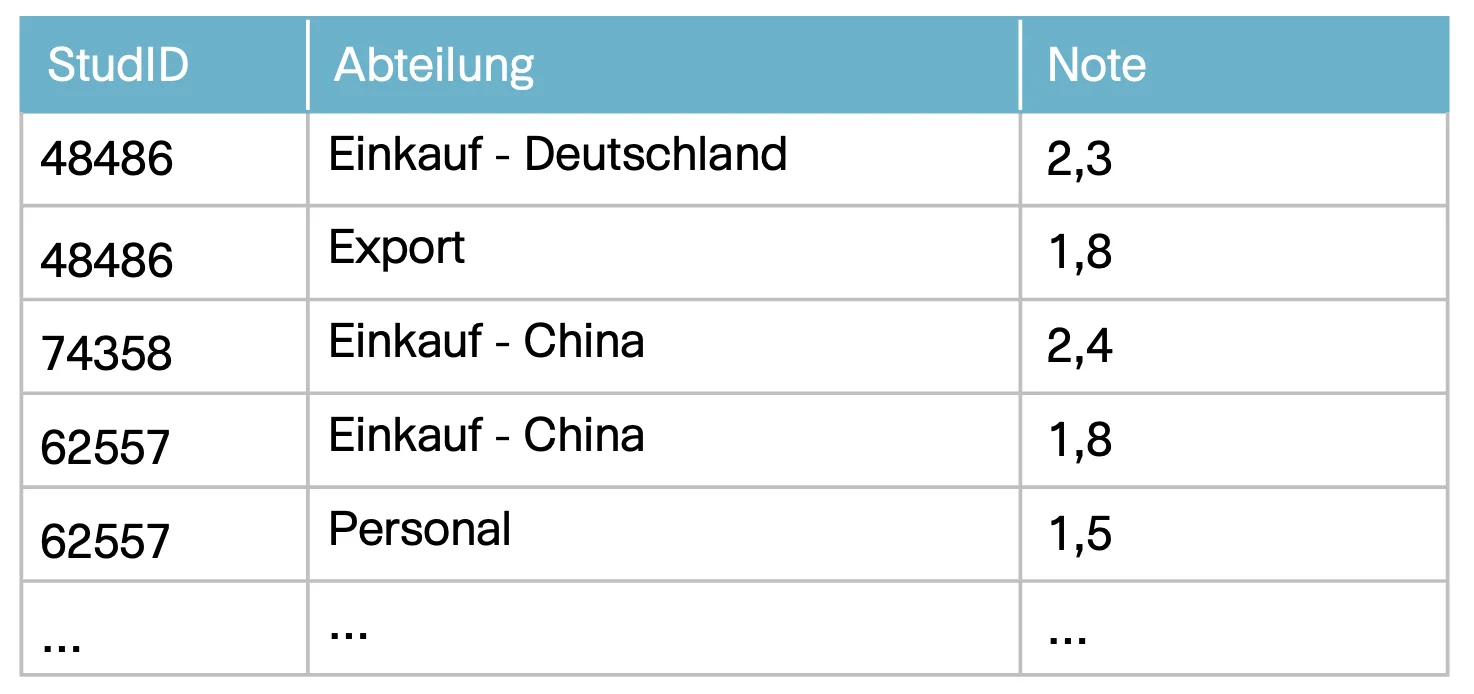
Alle Beispielinformationen werden zunächst als Facts bezeichnet. Durch den Modellierungsprozess werden aus Beispieldaten Sätze in natürlicher Sprache gebildet. Die Sätze, die einen elementaren Fakt ausdrücken, werden als Fact Expression bezeichnet. Durch die Gruppierung von Fact Expressions, die Fakten vom selben Typ ausdrücken, entstehen die Fact Types. Die Sätze der Fact Expressions, die in dieselbe Gruppe einsortiert wurden, haben eine ähnliche Struktur. Sie weisen exakt die gleiche Anzahl an Elementen auf, die eine Rolle im Fakt einnehmen.
Wird für jede dieser Rollen in der Fact Expression ein Platzhalter für eine beliebige Instanziierung der Rolle platziert, erhält der Modellierer ein Satzgerüst, in das er für die Platzhalter passende Daten der verknüpften Fact Types eintragen kann. Diese Satzgerüste bilden die Fact Expression Types. Weiterhin werden die Elemente, die eine Rolle in den Fact Types spielen, unterschieden in Object Types und Label Types. Alle Elemente, die ein bedeutsames Objekt (meaningful object [BZL00]) in der Domäne darstellen, sind als Object Types klassifiziert, alle Übrigen als Label Types. Ein Object Type benötigt immer eine Verbindung zu einem oder mehreren Label Types zur eindeutigen Identifikation.
Die gezeigten Beispieldaten verbalisiert der Domänenexperte. Dabei müssen die entstehenden Sätze korrekt und klar verständlich sein sowie immer nur einen elementaren Fakt ausdrücken. Beispielsweise ergibt der Satz „Der Student 48486 hat den Vornamen Hannes und studiert den Studiengang M.Sc.BWL.“ gleich zwei elementare Fakten:
- Der Student 48486 hat den Vornamen Hannes.
- Der Student 48486 studiert den Studiengang M.Sc.BWL.
Anhand der Sätze kann der Modellierer durch Sortieren und Analysieren Faktentypen bilden und Object bzw. Label Types identifizieren. Nachfolgend ist eine Beispielanalyse für den Faktentyp „Abteilungsnote“ gezeigt:
Fact Type
Abteilungsnote
Fact Expressions
Der Student 48486 hat in der Abteilung Einkauf-Deutschland die Note 2.3 erreicht.
Der Student 62557 hat in der Abteilung Einkauf-China die Note 1.8 erreicht.
Fact Expression Type
Der <Student> hat in der <Abteilung> die Note <Note> erreicht.
Object Types
Student, Abteilung
Label Types
Note
Durch die Analyse aller Beispielinformationen entstehen die gezeigten Modellelemente. Anschließend werden über die Geschäftsregeln die Constraints ermittelt und der Modelldefinition hinzugefügt.
Fact Types
-
Vorname von Student
-
Nachname von Student
-
Studiengang von Student
-
Abteilungsnote
Object Types
-
Student
-
Abteilung
-
Studiengang
Label Types
-
Vorname
-
Nachname
-
Note
-
StudID
-
Studiengangsname
-
Abteilungsname
Casetalk als unterstützendes Werkzeug für FCO-IM reduziert die Entwicklungszeit, indem es den Entwickler bei der Analyse der Datensätze und der Definition von Constraints unterstützt. Das finale FCO-IM-Modell für den Anwendungsfall von FastChangeCo:
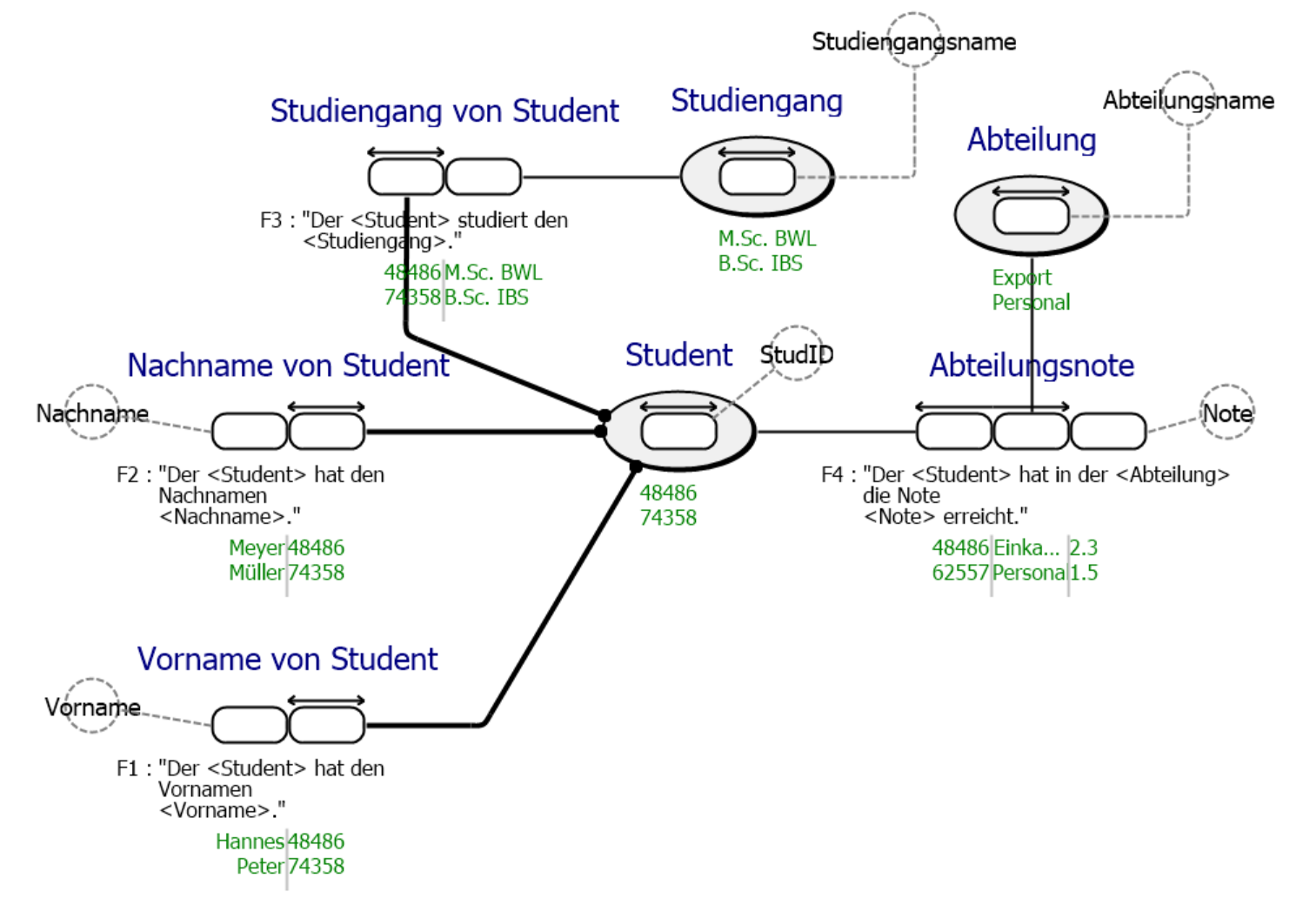
CaseTalk erstellt automatisch eine Dokumentation des Modells. Dadurch kann der Domänenexperte auch ohne Verständnis der grafischen Notation das Modell validieren.
Der Modellierer kann dieses FCO-IM-Modell mit Hilfe von CaseTalk durch Nutzung der GLR-Transformation in ein relationales Schema umwandeln und anschließend direkt DDL-Code zur Implementierung einer Datenbankstruktur im Core Data Warehouse erzeugen.
Fazit
Die FCO-IM-Methode liefert FastChangeCo eine qualitativ hochwertige, automatisch generierte Dokumentation in natürlicher Sprache, die der Fachexperte selbständig validieren kann. Nur relevante Elemente des Geschäftsfeldes werden anhand konkreter Beispielinformationen modelliert.
Anschließend kann das konzeptionelle Modell automatisch in ein redundanzfreies physisches, relationales Datenmodell für das Core Data Warehouse von FastChangeCo transformiert und in einem Datenbanksystem implementiert werden.
Die Beispieldaten können dabei zu Testzwecken direkt in das neue System übernommen werden. Durch den in FCO-IM übersichtlichen und exakt definierten Modellierungsprozess kann das Modell jederzeit um weitere Informationen erweitert werden. Diese Erweiterungen können wiederum direkt transformiert und implementiert werden.
Für FastChangeCo gestaltet sich so die Kommunikation zwischen Datenmodellierer und Domänenexperte über Informationen und das Modell sehr viel leichter und besser. Durch die Validierung konkreter Beispiele in natürlicher Sprache entstehen bei FastChangeCo bessere konzeptuelle Modelle und in der Folge bessere physische Datenmodelle mit einer hohen Datenqualität.
Mit der wachsenden Verbreitung von Fact-Oriented Modeling haben die in diesem Artikel vorgestellten Methoden eine gute Perspektive, vermehrt in Projekten eingesetzt zu werden. Darüber hinaus werden alle aufgezeigten Methoden weiterentwickelt (siehe [Hal15; ZEH15]).
Literatur
[BJR96] Booch, G. / Jacobson, I. / Rumbaugh, J.: The unified modeling language. Unix Review, 14. Jg., Nr. 13, 1996, S. 5
[BZL00] Bakema, G. / Zwart, J. P. / van der Lek, H.: Fully communication-oriented information modelling. Ten Hagen Stam 2000
[Che76] Chen, P. P. S.: The entity-relationship model – toward a unified view of data. ACM Transactions on Database Systems (TODS), 1(1),1976, S. 9–36
[Cod70] Codd, E. F.: A relational model of data for large shared data banks. Communications of the ACM, 13(6), 1970, S. 377–387
[Fal76] Falkenberg, E. D.: Concepts for modelling information. In: Proc. IFIP TC2/WG2.6, Working Conference on Modelling in Data Base Management Systems, 1976, S. 95–109
[Hal95] Halpin, T.: Conceptual schema and relational database design. 2. Aufl., Prentice Hall 1995
[Hal01] Halpin, T.: Information Modeling and Relational Databases: From Conceptual Analysis to Logical Design. Morgan Kaufmann 2001
[Hal05] Halpin, T.: ORM 2. In: OTM Confederated International Conferences: On the Move to Meaningful Internet Systems. Springer 2005, S. 676–687
[Hal15] Halpin, T.: Object-Role Modeling Fundamentals: A Practical Guide to Data Modeling with ORM. Technics Publications 2015
[NiC09] Nijssen, G. M. / Le Cat, A.: Kennis Gebaseerd Werken: de manier om kennis productief te Maken. PNA Publishing 2009
[TED24] Lerner, D.: FastChangeCo – A Fictitious Company. https://tedamoh.com/en/academy/fastchangeco, abgerufen am 12.6.2017
[TED17a] Lerner, D. / Volkmann, S.: Fact-Oriented Modeling (FOM) – Family, History and Differences. https://tedamoh.com/en/blog/data-modeling/53-fom/92-fact-oriented-modeling-fom-family-history-and-differences, abgerufen am 26.6.2017
[TED17b] Lerner, D.: Sketch Notes Reflections at TDWI Roundtable with FCO-IM. 30.1.2017, https://tedamoh.com/en/blog/48-tdwi-roundtable/85-sketch-notes-reflections-at-tdwi-roundtable-with-fco-im, abgerufen am 28.4.2017
[ZEH15] Zwart, J. P. / Engelbart, M. / Hoppenbrouwers, S.: Fact Oriented Modeling with FCO-IM: Capturing Business Semantics in Data Models with Fully Communication Oriented Information Modeling. Technics Publications 2015