
Nach dem Advanced Data Vault 2.0 Boot Camp fand im Anschluss das World Wide Data Vault Consortium statt, das allererste überhaupt. Ein historisches Ereignis. Ja, vor allem auch deswegen, wie viele geniale und intelligente Menschen die Mühen auf sich nahmen nach St. Albans, Vermont, USA zu kommen. Und wirklich weltweit: aus den USA, Kanada, Australien, Norwegen, Holland und Deutschland kamen die Teilnehmer, um von Dan Linstedt das Neueste über Data Vault 2.0 zu hören, aber auch den Keynotes und den viele Vorträgen zu folgen und sich in Networking Sessions untereinander auszutauschen.
Für alle Tweeds und noch mehr Infos: Geht auf Twitter mit #WWDVC!
Tag 1
@KentGraziano There is so much brain power in the #BBBT member group, it's scary! #WWDVC #DataVault
— Oliver Cramer (@proximaastra) 20. März 2014
 Dan Linstedt - AnnouncmentsIn seiner Keynote stellt Dan Linstedt die Neuigkeiten über Data Vault 2.0 vor: Integration von NoSQL in die Architektur von Data Vault 2.0, Verwendung von Hashes und Managed Self Service BI. Neue Ankündigung zu Partnerschaften gab es ebenfalls. Die neue Firma RapidGenDS von Dan und Sandjay hat eine exklusive Partnerschaft mit AnalyticsDS und stellt dieser die Templates des Data Vault ETL zur Verfügung.
Dan Linstedt - AnnouncmentsIn seiner Keynote stellt Dan Linstedt die Neuigkeiten über Data Vault 2.0 vor: Integration von NoSQL in die Architektur von Data Vault 2.0, Verwendung von Hashes und Managed Self Service BI. Neue Ankündigung zu Partnerschaften gab es ebenfalls. Die neue Firma RapidGenDS von Dan und Sandjay hat eine exklusive Partnerschaft mit AnalyticsDS und stellt dieser die Templates des Data Vault ETL zur Verfügung.
Sandjay Pande gibt im Anschluss einen kurzen Überblick über BigData, im speziellen Hadoop. Unter Data Vault 2.0 ist Hadoop als Archiving, Staging und Ergänzung im DWH (Satelliten) gedacht.
„A Data Lake is a garbage dump.“
Am ersten Tag gab es genug Zeit zum Networking. Es macht sehr viel Spaß mit den „Brains“ aus der Data Vault Szene zu sprechen und Gedanken auszutauschen.
Nach dem Mittag zeigte uns Kent Graziano in seinem Vortrag How I Save My Clients $$$ by Creating the Best Data Model the First Time wie man mit Check-Listen, Regelwerken und Namenskonventionen Projekte schneller und effizienter macht.
Thank you @KentGraziano for your great presentation. Think #scrum #WWDVC @DV_Modeling - We will create the best #datamodels in the #future
— Kwitschi (@Kwitschi) 20. März 2014
Eine weitere Networking Session leitet über zur Skype-Session mit Bill Inmon. Er stellt sich den Fragen der anwesenden Geeks und philosophiert über TextAnalytics, Ontologien und Taxonomien sowie wohin sich das CIF in den kommenden 10 Jahren entwickeln könnte.
#WWDVC #bigdata sending structured data into hadoop makes it unstructured. inmon: nobody would want todo that
— Torsten Glunde (@tglunde) 20. März 2014
 Im Anschluss präsentiert Raphael Klebanow von WhereScape. In einer genialen Demo sieht man, wie Data Vault in RED und 3D angewendet und automatisiert wird.
Im Anschluss präsentiert Raphael Klebanow von WhereScape. In einer genialen Demo sieht man, wie Data Vault in RED und 3D angewendet und automatisiert wird.
@RaphaelKlebanov from @Wherescape doing a great job fielding difficult questions about DWH Automation at #WWDVC meta data driven ETL
— Tom Breur (@tombreur) 20. März 2014
Tag 2
Der erste Tag hat wirklich so viele Informationen in sich gehabt, dass man dachte, es könnte nicht noch mehr werden. Aber doch, der zweite Tag brachte unsere Gehirne fast zum Explodieren. Doch der Reihe nach.
#WWDVC a #DataVault without real business keys cannot deliver real business value. @dlinstedt
— Kent Graziano (@KentGraziano) 21. März 2014
 Statt der Gruppenarbeiten hat Dan Linstedt einen noch tieferen Einblick in Data Vault 2.0 gegeben, in einem überirdischen Tempo. Für uns Teilnehmer aus dem Advanced Data Vault 2.0 Bootcamp war es zwar eine Wiederholung, aber in einer noch nie erlebten Geschwindigkeit. Wow. Diese Präsentation wird es auch nur in dem Kurs geben. Eine der interessantesten Neuerungen ist, dass Dan Linstedt von Information Mart spricht, nicht mehr von Data Mart. Informationen sind es, die der User nutz. (Roh-) Daten speichert das DWH im Core.
Statt der Gruppenarbeiten hat Dan Linstedt einen noch tieferen Einblick in Data Vault 2.0 gegeben, in einem überirdischen Tempo. Für uns Teilnehmer aus dem Advanced Data Vault 2.0 Bootcamp war es zwar eine Wiederholung, aber in einer noch nie erlebten Geschwindigkeit. Wow. Diese Präsentation wird es auch nur in dem Kurs geben. Eine der interessantesten Neuerungen ist, dass Dan Linstedt von Information Mart spricht, nicht mehr von Data Mart. Informationen sind es, die der User nutz. (Roh-) Daten speichert das DWH im Core.
- You can’t optimize what you can’t measure
- You can’t measure what you can’t identify
- You can’t identify what you don’t define
- You can’t define what you don’t understand
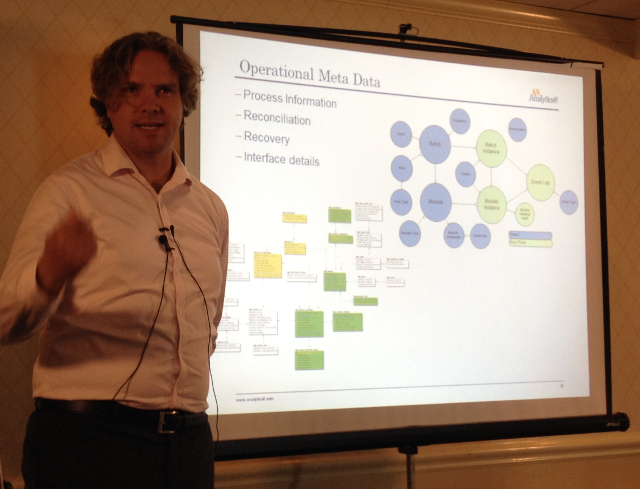 Roelant Vos beeindruckte die Zuhörer mit einer Demonstration seines Automationsframework für Data Vault inkl. seiner Sicht auf die Architektur. Ein Aspekt dabei ist die Verwendung einer historischen Staging Area, parallel zur Staging Area. Der große Nutzen davon ist, dass man z.B. einen Initial Load dort speichern kann. Somit ist ein Quellsystem von wiederholten Anfragen nach einem Initial Load entlastet.
Roelant Vos beeindruckte die Zuhörer mit einer Demonstration seines Automationsframework für Data Vault inkl. seiner Sicht auf die Architektur. Ein Aspekt dabei ist die Verwendung einer historischen Staging Area, parallel zur Staging Area. Der große Nutzen davon ist, dass man z.B. einen Initial Load dort speichern kann. Somit ist ein Quellsystem von wiederholten Anfragen nach einem Initial Load entlastet.
Auch geht Roelant auf die Wichtigkeit von Namenskonventionen ein: „Naming convention has to be 100% right to start automation, if not automation will fail!“
#WWDVC can save 80% time by automating the development of ETL using tools and templates. #DataVault 2.0. That saves a bunch of $$$$ folks!
— Kent Graziano (@KentGraziano) 21. März 2014
#WWDVC gotta say this: there is NO good excuse for not auto generating your ETL for a #DataVault. IMO it borders on being irresponsible.
— Kent Graziano (@KentGraziano) 21. März 2014
 Ein absoluter Buffer Overflow erzeugte Doug Needham mit seiner Mathematik zu Data Vault. Mit seinen mathematischen Formeln trägt Doug zur Qualität eines Data Vault bei, da damit eine Validierung der geladenen Daten möglich ist.
Ein absoluter Buffer Overflow erzeugte Doug Needham mit seiner Mathematik zu Data Vault. Mit seinen mathematischen Formeln trägt Doug zur Qualität eines Data Vault bei, da damit eine Validierung der geladenen Daten möglich ist.
Doug, The Data Guy: “The data has to be at the right place, at the right time for the right person.”
#WWDVC @dougneedham Data needs to be at the right place, at the right time to the right person #datavault
— Sanjay Pande (@sanjay_pande) 21. März 2014
 Mit dem zweiten Vortrag von Kent Graziano erhalten wir eine tiefgehende Einführung in den kostenlosen Oracle Software Developer Data Modeler (SDDM). Beeindruckend, was dieser inzwischen kann. Ich wünschte, man könnte damit auch Teradata-DDLs generieren.
Mit dem zweiten Vortrag von Kent Graziano erhalten wir eine tiefgehende Einführung in den kostenlosen Oracle Software Developer Data Modeler (SDDM). Beeindruckend, was dieser inzwischen kann. Ich wünschte, man könnte damit auch Teradata-DDLs generieren.
Genial, wie einfach der Oracle SDDM Namenskonventionen umsetzen kann und diese auch noch prüft. Das hilft dem Datenmodellierer ungemein, z. B. bei der Transformation eines Logischen Datenmodells in ein Physisches Datenmodell oder der Generierung von DDLs. Die Blogs von Jeff Smith und Kent Graziano sind prima Quellen, wenn ihr mehr darüber wissen wollt.
AnalytixDS sponserte einen großartigen Abendevent mit einer Präsentation Ihres Tools im Twiggs. Dafür war ein kompletter Raum abgetrennt. Tom, der Vertriebler, sang noch für die versammelten Gäste. Das tat gut, um unseren Gehirnen eine Pause vom Tag zu gönnen und zu entspannen.

Tag 3
Tag 3 beginnt mit einer Keynote von Tom Breur über Data Vault & Agile BI. Tom brachte es mit einigen, wenigen Kernaussagen auf den Punkt, was Agile BI ist:
- Agil zu sein, bedeutet kleine Brötchen zu backen
- Aufwandsschätzungen meint kein Vertrauen – Vertrauen bedeutet keine Schätzung
- Liefere früh und oft in kleinen Zyklen
Schaut euch die Tweeds auf Twitter an -> #WWDVC
„Quick & dirty - Has nothing to do with agile: most people forget about the quick, that they have to live with the dirty!“
Um vom annähernd ersten Moment eines Projekts agil zu sein, sollte man nur einen Hub mit einem Satelliten liefern (Stg, Core), um direkt einen Mehrwert an den oder die Fachbereiche zu liefern. In diesem frühen Stadium ist der Mehrwert auf das Data Profiling der Daten ausgerichtet, noch nicht in der Bereitstellung eines Information Marts.
"Make it easy and less expensive for business users to change their mind" - @tombruer #WWDVC #datavault
— Sanjay Pande (@sanjay_pande) 22. März 2014
In der Customer Case Study, ein Vortrag von DataBlueprint, zeigten Josh Bartels und John Sells wie sie die Probleme Ihrer Kunden mit Data Vault lösten und damit auch noch viele $$$ einsparen konnten. Toll war für alle, dass überall die gleichen Herausforderungen in den Projekten bestehen, mehr oder weniger intensiv.
#WWDVC lovely data wasteland. No model, no doc, no relationships and only one person who understands it. Yikes! pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/zxsHPLkmW2
— Kent Graziano (@KentGraziano) 22. März 2014
Als letzte Präsentation des #WWDVC stellte die deutsche Firma MID sein Tool Innovator vor. Wow, beeindruckend was MID hier auf die Beine gestellt hat. Modellierung, Mapping und Generierung sowie eine übersichtliche Darstellung der Modelle. Sehr gut hat mir dabei die nahtlose Darstellung der Modelle von Stage über Core bis in den Mart gefallen. Der Innovator ist einen Blick wert, wenn man ein Datenmodellierungstool sucht, das auch die Automatisierung unterstützt.
#wwdvc demo of innovator by @midgmbh looking forward to #experimentation. pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/6dWkWq4dII
— Doug Needham (@dougneedham) 22. März 2014
Dan Linstedt schließt die Konferenz mit seinen Closing Thoughts und Memorable Moments. Ein gelungener Abschluss eines wirklichen gelungen Events. Es lohnt sich alle Tweeds zum #WWDVC zu lesen, ok ich wiederhole mich.
#wwdvc memorable #moments pic.7905d1c4e12c54933a44d19fcd5f9356-gdprlock/wyzUw2gyRH
— Doug Needham (@dougneedham) 22. März 2014
Abschließend noch ein Bild des gefrorenen Sees bei St. Albans. Ja, es war richtig kalt dort!

Bis dann,
Euer Dirk
The trip is over. Just right arrived at Frankfurt Airport, back in Germany. Had a good time at the #WWDVC and #DataVault 2.0 boot camp.
— Dirk Lerner (@DV_Modeling) 24. März 2014
Persönliche Eindrücke:



