
Do you want to learn something about data modelling with Steve Hoberman? You want to explore new methods like Data Vault 2.0, Anchor Modeling, Data Design, DMBOK and many more? E.g. a keynote where Dan Linstedt, Lars Rönnbäck and Hans Hultgren talks together, and another one with Bill Inmon?

Last week, there was it again. A meeting of Data Vault geeks and interested people in Data Vault! And again in the wonderful area of Vermont, USA. But these year we hat +30°C compared to last year’s -20°C. In Stowe, Vermont, the conference was held in the wonderful Trapp Family Lodge. To give you some more insights I’ll embed some of the tweets. If you want read the full timeline, go here!
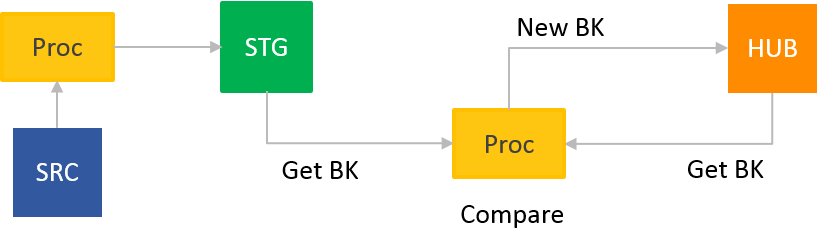
KISS –
K – Keep (Data Vault)
I – It (ETL in your Data Warehouse)
S – Small (lightweight processes aka short and easy SQL)
S – and simple (easy Inserts and Updates)
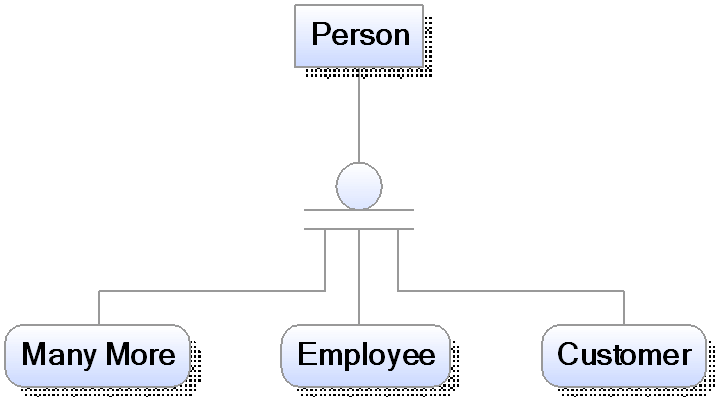
Wie bereits in meinem Blogpost Modellierung oder Business Rule beschrieben ist es notwendig sich bei der Datenmodellierung über Geschäftsobjekte, die Wertschöpfungskette, fachliche Details und die Methodik des Modellierens einige Gedanken zu machen.
Oder doch nicht? Kann ich mit Data Vault einfach loslegen? Schließlich ist Data Vault auf den ersten Blick ganz einfach. Drei Objekte: HUBs, LINKs und SAT(elliten), einem einfachen Vorgehensmodell und ein paar wenige Regeln. Brauche ich für Data Vault noch die Datenmodellierung?
Zum ersten Mal gibt es in Deutschland den Data Vault Day, am 11. März 2015. Das BI-Podium bringt uns einen ganzen Tag nur Data Vault, pures Data Vault :-) .
Auch Dan Linstedt, Begründer der Data Vault Methode, wird dabei sein. Lasst euch nicht die Chance entgehen ihn Live zu hören. Es ist eine der wenigen Möglichkeiten in Deutschland. Darüber hinaus könnt ihr direkt, mit ihm selbst, in den Networking-Slots reden, Fragen stellen oder euch einfach ein Autogramm geben lassen.
Oder wie ich einen HotSpot erstellte!
Manchmal ist es merkwürdig mit den Konferenzhotels. Genau in diesem Moment sitze ich in einem, mit in Deutschland. Überall drumherum gibt es LTE, nur hier im Hotel Edge. Hmm, „OK“ denkt sich der erfahrene Hotelgast, kein Problem: Schließlich gibt es kostenloses WLAN.
Ha, ja, das gibt es, aber nicht in den Zimmern oder nur bei richtige Windrichtung und Wetterlage. So der Haustechniker. Nunja, da habe ich wohl gerade das falsche Wetter erwischt.

Past, present and future, where did I speak and where will I speak at conferences?
Since my calendar fills up more and more with presentations at conferences I'll give you a summary to keep track on it. Some of them are already confirmed, for others I've submitted my abstracts but yet not confirmed.
Seite 10 von 13