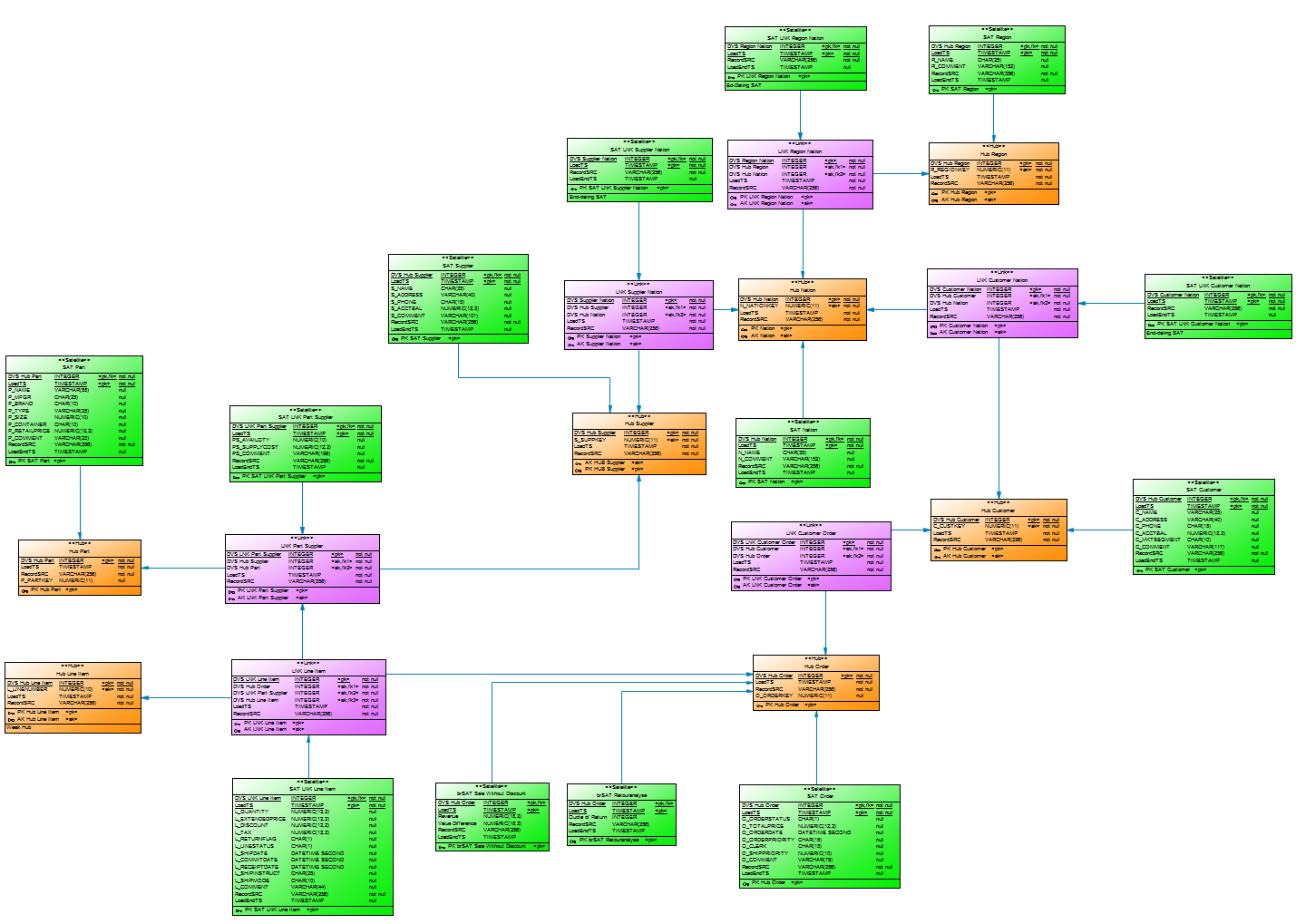
Over the last few weeks, Mathias Brink and I have worked hard on the topic of Data Vault on EXASOL.
Our (simple) question: How does EXASOL perform with Data Vault?
First, we had to decide what kind of data to run performance tests against in order to get a feeling for the power of this combination. And we decided to use the well-known TPC-H benchmark created by the non-profit organisation TPC.
Second, we built a (simple) Data Vault model and loaded 500 GB of data into the installed model. And to be honest, it was not the best model. On top of it we built a virtual TPC-H data model to execute the TPC-H SQLs in order to analyse performance.
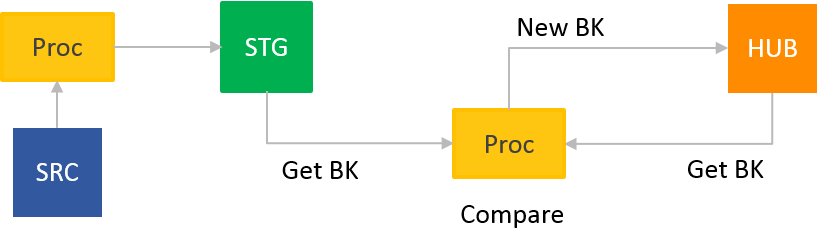
KISS –
K – Keep (Data Vault)
I – It (ETL in your Data Warehouse)
S – Small (lightweight processes aka short and easy SQL)
S – and simple (easy Inserts and Updates)
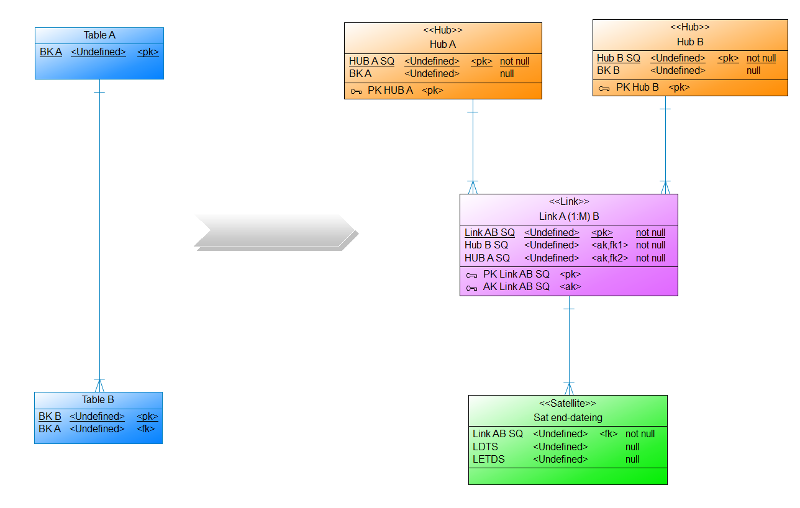
Auf dem 1. DDVUG Treffen hatten wir ein interessante Diskussion darüber, wo eigentlich die Datenmodellierung aufhört und Business Rules beginnen. Aufgehängt hatte sich dies an meiner Präsentation, in der es um einen Link ging, der eine 1:M (Hub A – (M) Link (1) – Hub B) Relation repräsentiert und über einen bi-temporalen Satelliten den gesteuert (end-dating) wird. So darf für jeden Eintrag im Hub B nur eine aktive Relation im Link existieren. Die Daten für das End-dating des Links kamen im von mir aufgeführten Beispiel bereits aus dem Quellsystem (Blogpost folgt bald).
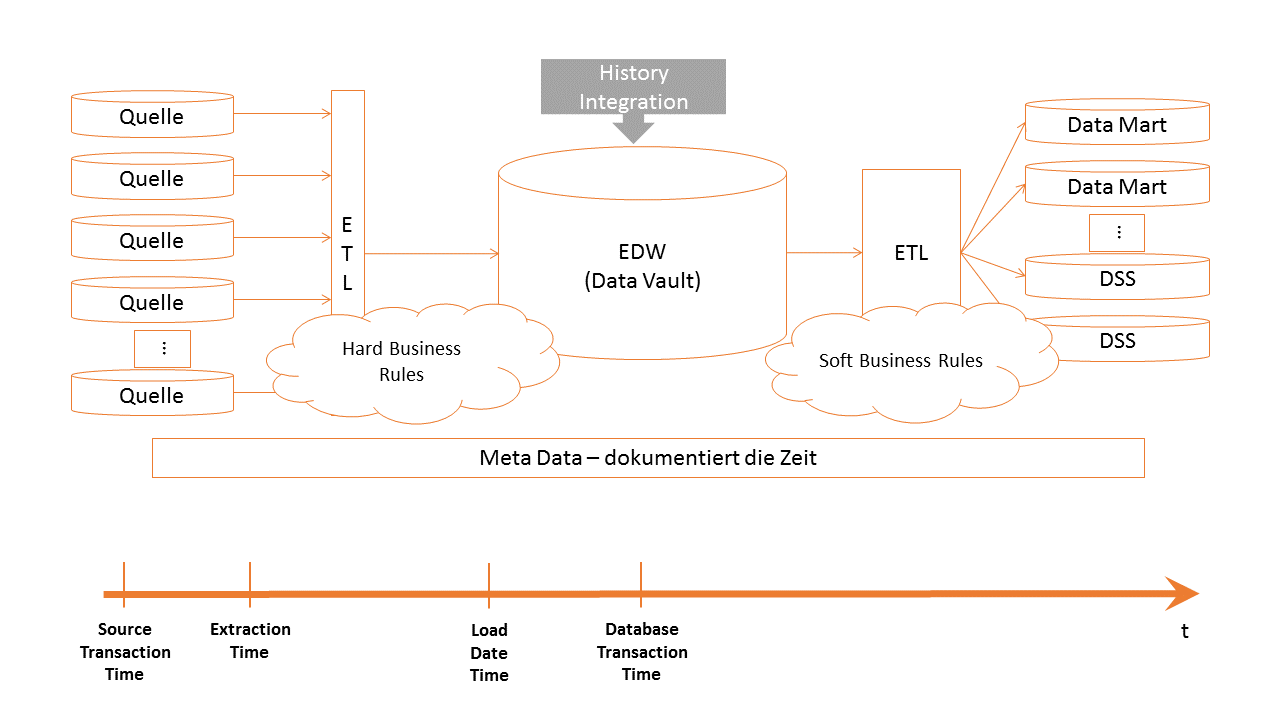
Welche Zeit nehme ich für die Timelines in den Data Vault Entitäten? In meinen Projekten stellt sich immer wieder diese Frage. Dokumentiert das LoadDate im HUB, im LINK und im SAT den Load Date TimeStamp (LDTS) nach Dan Linstedt, oder doch die Transaction Time zu der Daten im Quellsystems entstanden sind? Oder besser die Extraktionszeit? Oder die Transaktionszeit der Datenbank1) zu der die Datenbank die Datensätze in die Tabellen speichert? Nicht einfach zu beantworten, oder?
Page 3 of 6