Immer wieder kommt in Projekten die Frage auf, besser gesagt die Diskussion, ob Constraints in der Datenbank physisch sinnvoll sind oder nicht. Meist gibt es Vorgaben von DBAs oder durchsetzungsstarken ETLern, die eine generelle Abneigung gegen Constraints zu haben scheinen, dass Constraints nicht erwünscht sind. OK, diese Woche wurde mir wieder das Gegenteil bewiesen. Doch wie heißt es so schön: Ausnahmen ...
Auf dem #WWDVC und im Advanced Data Vault 2.0 Boot Camp haben wir ebenfalls über dieses Phänomen gesprochen. Das scheint weltweit zu existieren. Dazu hat kurz nach dem #WWDVC auch Kent Graziano einen Blogpost verfasst. Auf LinkedIn gab es dazu einige Kommentare.
Gut, wie argumentiert man am besten, bzw. was sind eigentlich die Vor- und Nachteile Constraints zu verwenden?
Jaja, ich weiß, eigentlich sind Constraints nur dazu da um ETLer daran zu hindern ihre Daten schnell in die Datenbank zu bekommen und um in Ladeketten für Probleme zu sorgen. Und natürlich werden alle Checks (die Constraints übernehmen sollten) von extra entwickelten Routinen in den ETL-Jobs gemacht. Also keine Notwendigkeit darüber zu schreiben? Alles geklärt, oder?
Ganz so sehe ich das nicht. In den Diskussionen sollte zuerst klar sein, über welche Art von Constraints eigentlich geredet wird:
- NOT NULL Constraint (ja, das ist auch ein Constraint)
- Check Constraint
- Unique Constraint
- Foreign Key Constraint
- Primary Key Constraint
Hmm, und natürlich lieber erst gar nicht von Deletes on Cascade und Ähnlichem anfangen. Das kann richtig Ärger machen, wenn man nicht weiß was man tut, oder?
Was ist das Ziel eines Data Warehouse? Primär Daten zu laden oder auch Daten und Information bereitzustellen? Aus meiner Sicht ist eines der größten Ziele eines Data Warehouse Daten und Information so schnell wie möglich den Anwendern zu Verfügung zu stellen, im Sinne der Abfragegeschwindigkeit. Per SQL, Bericht, Dashboard oder wie auch immer. Wenn dem nicht so wäre, bräuchte man die vielen Varianten von InMemory Datenbanken nicht.
Gut, kommen wir zu den Vor- und Nachteilen:
- Nachteil 1: Sie erzeugen je nach Variante mehr oder weniger Overhead in der Datenbank. Das kostet Zeit beim Laden der Daten.
- Nachteil 2: Sie lassen ETL-Ketten abbrechen, wenn die Daten nicht passen. Sehr ärgerlich und bedeutet im Betrieb Aufwand.
- Vorteil 1: Sie beschleunigen die Abfragegeschwindigkeit und helfen den Optimizern nicht unerheblich, siehe dazu das Beispiel unten.
- Vorteil 2: Foreign Key Constraints sind bereits eine QS-Prüfung, die Datenbanken frei Haus liefern. Ich muss nicht aufwändig ETL-Routinen entwickeln, die diese vorhandenen Prüfungen nachbauen.
- Vorteil 3: Direkte Rückmeldung, wenn Probleme in den Daten auftreten.
- Vorteil 4: Speziell im Data Vault Datenmodell können so ETL-Prozesse einer QS unterzogen werden. Data Vault ETL Prozesse müssen durch ihre Natur immer so funktionieren, dass sie keine Foreign Key Constraint Verletzungen erzeugen.
Aus meiner Sicht überwiegen die Vorteile klar. Sollte beim Laden von großen Datenmengen Performanceprobleme auftreten, hat man in der Regel die Möglichkeit die Constraints zu deaktivieren und nach dem Laden wieder zu aktivieren.
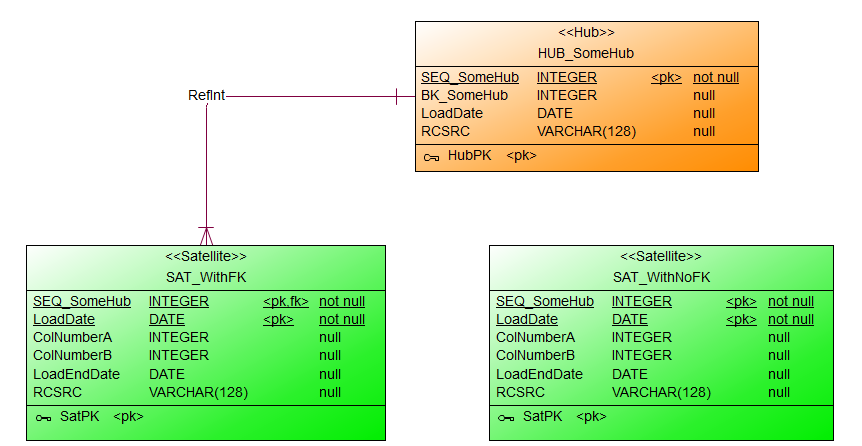
Beispiel mit Hub und Satellite
Ich möchte euch ein konkretes Beispiel zeigen, wie sich ein Foreign Key Constraint auf der Teradata V14 auf den Explain (Select) auswirkt.
Dafür habe ich einen Hub mit zwei Satelliten (mit und ohne FK-Constraint) angelegt:
SEQ_SomeHub INTEGER NOT NULL,
BK_SomeHub INTEGER,
LoadDate DATE,
RCSRC VARCHAR(128),
CONSTRAINT HubPK
PRIMARY KEY (SEQ_SomeHub)
);
SEQ_SomeHub INTEGER NOT NULL,
LoadDate DATE NOT NULL,
ColNumberA INTEGER,
ColNumberB INTEGER,
LoadEndDate DATE,
RCSRC VARCHAR(128),
CONSTRAINT SatPK
PRIMARY KEY (SEQ_SomeHub,LoadDate),
CONSTRAINT RefInt
FOREIGN KEY (SEQ_SomeHub) REFERENCES WITH NO CHECK OPTION HUB_SomeHub(SEQ_SomeHub)
);
SEQ_SomeHub INTEGER NOT NULL,
LoadDate DATE NOT NULL,
ColNumberA INTEGER,
ColNumberB INTEGER,
LoadEndDate DATE,
RCSRC VARCHAR(128),
CONSTRAINT SatPK
PRIMARY KEY (SEQ_SomeHub,LoadDate)
);
Der folgende Explain zeigt den Query Plan für ein vereinfachten SELECT mit einem Join zwischen dem Hub HUB_SomeHub und dem Satelliten SAT_WithNoFK. Beachtet dabei die Schritte 3-5.
SELECT HUB_SomeHub.SEQ_SomeHub,
SAT_WithNoFK.ColNumberA,
MAX(SAT_WithNoFK.ColNumberB)
FROM HUB_SomeHub,
SAT_WithNoFK
GROUP BY HUB_SomeHub.SEQ_SomeHub,
SAT_WithNoFK.ColNumberA
WHERE HUB_SomeHub.SEQ_SomeHub = SAT_WithNoFK.SEQ_SomeHub
--AND SAT_WithNoFK.LoadEndDate = '2999-12-31'
ORDER BY 1;
Expl.
1) First, we lock a distinct DLERNER.pseudo table for read on aRowHash to prevent global deadlock for DLERNER.TableWithNoFK.
2) Next, we lock a distinct DLERNER.pseudo table for read on a
RowHash to prevent global deadlock for DLERNER.SomeTable.
3) We lock DLERNER.TableWithNoFK for read, and we lock
DLERNER.SomeTable for read.
4) We do an all-AMPs RETRIEVE step from DLERNER.TableWithNoFK by way
of an all-rows scan with a condition of (NOT
(DLERNER.TableWithNoFK.ColNumberB IS NULL)) into Spool 4
(all_amps), which is redistributed by the hash code of (
DLERNER.TableWithNoFK.ColNumberB) to all AMPs. Then we do a SORT
to order Spool 4 by row hash. The size of Spool 4 is estimated
with low confidence to be 2 rows (50 bytes). The estimated time
for this step is 0.01 seconds.
5) We do an all-AMPs JOIN step from Spool 4 (Last Use) by way of a
RowHash match scan, which is joined to DLERNER.SomeTable by way of
a RowHash match scan with no residual conditions. Spool 4 and
DLERNER.SomeTable are joined using a merge join, with a join
condition of (DLERNER.SomeTable.ColNumberPK = ColNumberB). The
result goes into Spool 3 (all_amps), which is built locally on the
AMPs. The size of Spool 3 is estimated with index join confidence
to be 2 rows (54 bytes). The estimated time for this step is 0.05
seconds.
6) We do an all-AMPs SUM step to aggregate from Spool 3 (Last Use) by
way of an all-rows scan , grouping by field1 (
DLERNER.SomeTable.ColNumberPK ,DLERNER.TableWithNoFK.ColNumberA).
Aggregate Intermediate Results are computed locally, then placed
in Spool 5. The size of Spool 5 is estimated with low confidence
to be 2 rows (82 bytes). The estimated time for this step is 0.04
seconds.
7) We do an all-AMPs RETRIEVE step from Spool 5 (Last Use) by way of
an all-rows scan into Spool 1 (group_amps), which is built locally
on the AMPs. Then we do a SORT to order Spool 1 by the sort key
in spool field1 (DLERNER.SomeTable.ColNumberPK). The size of
Spool 1 is estimated with low confidence to be 2 rows (66 bytes).
The estimated time for this step is 0.04 seconds.
-> The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.15 seconds.
Nun dieselbe Query, jedoch mit dem Satelliten SAT_WithFK und einen Foreign Key Constraint. Der Optimizer erkennt jetzt, dass die Schritte 3 – 5 überflüssig sind und optimiert entsprechend den Query Plan. Die geschätzte Zeit des Optimizer zur Ausführung der Query beträgt jetzt nur noch 50% der Query ohne Foreign Key Constraint. Selbst in meiner Virtual Machine war diese einfach Query mit Foreign Key Constraint bei jedem Test schneller als ohne.
SELECT HUB_SomeHub.SEQ_SomeHub,
SAT_WithFK.ColNumberA,
MAX(SAT_WithFK.ColNumberB)
FROM HUB_SomeHub,
SAT_WithFK
GROUP BY HUB_SomeHub.SEQ_SomeHub,
SAT_WithFK.ColNumberA
WHERE HUB_SomeHub.SEQ_SomeHub = SAT_WithFK.SEQ_SomeHub
--AND SAT_WithFK.LoadEndDate = '2999-12-31'
ORDER BY 1;
Expl.
1) First, we lock a distinct DLERNER.pseudo table for read on aRowHash to prevent global deadlock for DLERNER.TableWithFK.
2) Next, we lock DLERNER.TableWithFK for read.
3) We do an all-AMPs SUM step to aggregate from DLERNER.TableWithFK
by way of an all-rows scan with a condition of (NOT
(DLERNER.TableWithFK.ColNumberB IS NULL)) , grouping by field1 (
DLERNER.TableWithFK.ColNumberB ,DLERNER.TableWithFK.ColNumberA).
Aggregate Intermediate Results are computed locally, then placed
in Spool 3. The size of Spool 3 is estimated with low confidence
to be 2 rows (82 bytes). The estimated time for this step is 0.04
seconds.
4) We do an all-AMPs RETRIEVE step from Spool 3 (Last Use) by way of
an all-rows scan into Spool 1 (group_amps), which is built locally
on the AMPs. Then we do a SORT to order Spool 1 by the sort key
in spool field1 (DLERNER.TableWithFK.ColNumberB). The size of
Spool 1 is estimated with low confidence to be 2 rows (66 bytes).
The estimated time for this step is 0.04 seconds.
-> The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.08 seconds.
Und solltet Ihr den Oracle SQL Developer verwenden, gibt es noch einen guten Grund für Foreign Key Constraints: Lest dazu den Blogpost von ThatJeffSmith.
So long,
Euer Dirk