Data Modeling
-
1:M – Link: Modellierung oder Business Rule?
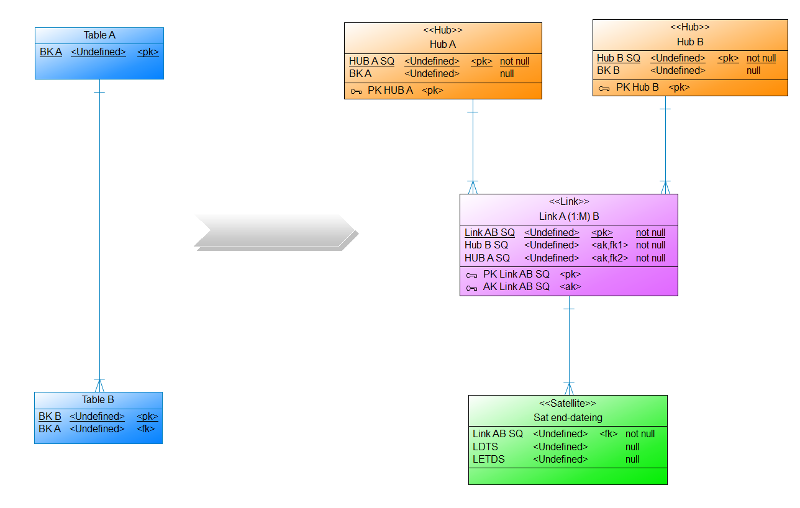
Auf dem 1. DDVUG Treffen hatten wir ein interessante Diskussion darüber, wo eigentlich die Datenmodellierung aufhört und Business Rules beginnen. Aufgehängt hatte sich dies an meiner Präsentation, in der es um einen Link ging, der eine 1:M (Hub A – (M) Link (1) – Hub B) Relation repräsentiert und über einen bi-temporalen Satelliten den gesteuert (end-dating) wird. So darf für jeden Eintrag im Hub B nur eine aktive Relation im Link existieren. Die Daten für das End-dating des Links kamen im von mir aufgeführten Beispiel bereits aus dem Quellsystem (Blogpost folgt bald).
-
5th anniversary of TEDAMOH

Dear readers of my blog,
five years ago a long cherished idea of mine became reality. On July 1, 2017, TEDAMOH saw the light of day.
-
A comment
In recent weeks I have read so many pessimistic and negative articles and comments in the social media about the state of data modeling in companies in Germany, but also worldwide.
Why? I don't know. I can't understand it.
I know many companies that invest a lot of time in data modeling because they have understood the added value. I know many companies that initially rejected data modeling as a whole, but understood its benefits through convincing and training.
Isn't it the case that we (consultants, managers, project managers, subject-matter experts, etc.) should have a positive influence on data modeling? To support our partners in projects in such a way that data modeling becomes a success? If we ourselves do not believe that data modeling is a success, then who does?
-
An open and honest feedback on “13 tips …”

A few weeks ago I received a surprisingly open and honest feedback on my recently published article "13 tips...". I never ever expected that! After a short email exchange, I was allowed to publish the feedback anonymously. Below is the incredible feedback[3]. You see, you are not alone with the challenges of a Data Vault project:
Hi Dirk
Thanks for sending me the English version of the paper. I'm based in […] [1] and Data Vault is not generally established here yet. -
Articles
All articles I wrote about data warehousing, Data Vault, data modeling and more.
Enjoy reading and your comments are welcome.
-
Blog
-
CDC verstehen, um Daten in Data Vault zu löschen

Change Data Capture erkennt Änderungen an Daten. Im Falle von gelöschten Daten stellt sich die Frage: Wie sollten wir Löschungen in Data Vault verwalten?
-
Change default value

At FastChangeCo, the data modelers within the Data Management Center of Excellence (DMCE) team are constantly designing new database objects to store data. One of the data modelers on the team is Xuefang Kaya. When she takes a new user story/task, she usually models multiple tables, their columns, and specifies a data type for each column.
-
Coaching Serie

/ SECRET SPICE - COACHING Serie
Coaching - Wie denn nun?
In loser Folge veröffentliche ich meine Gedanken und Erfahrungen rund um Datenmodellierung, temporale Daten oder viele andere Dinge aus der Welt des Coachings. Dazu gehören für mich Lösungsansätze unterschiedlichster Art, die manchmal generell, manchmal ausschließlich für eine bestimmte Situation geeignet sind.
Sehr oft wichtig und nicht zu vernachlässigen sind die fachlichen Anforderungen, die den Lösungsansätzen zugrunde liegen.
Wie die bereits veröffentlichte Serie zum PowerDesigner und die Serie zu temporalen Daten ist diese Serie für mich eine Art, kleine Schätze aus meiner Coaching-Welt, das ‘Secret Spice’, mit euch zu teilen.
In dieser Serie werdet ihr wahrscheinlich nicht so oft wie in den anderen Serien auf die Teammitglieder des Data Management Center of Excellence (DMCE) meines Lieblingskunden FastChangeCoTM treffen.
-
Coaching Series
/ SECRET SPICE - COACHING SerieS
Coaching - How to do it?
In loose order I publish my thoughts and experiences around data modeling, temporal data or many other things from the world of coaching. For me, this includes approaches to solutions of the most varying kinds, which are sometimes suitable in general, sometimes exclusively for a specific situation.
Very often important and not to be disregarded are the business requirements on which the approaches to a solution are based.
Like the already published series on PowerDesigner and the series on temporal data, this series is a way for me to share with you little treasures from my coaching world, the 'Secret Spice'.
In this series, you probably won't run into the Data Management Center of Excellence (DMCE) team members from my favorite customer, FastChangeCoTM, as often as in the other series.
-
Customize table comments
In several projects, FastChangeCo's data modelers on the Data Management Center of Excellence (DMCE) team had an issue with the way PowerDesigner generates comments for tables and columns for the SQL Server database. Xuefang Kaya (one of the data modelers on the team), asked about the problems, says to the DMCE team:
-
Das Ziel: ganzheitliche Gestaltung

Data Vault im Einsatz beim Gutenberg RechenzentrumIm Rahmen einer umfassenden Neugestaltung entsteht beim Gutenberg Rechenzentrum in Hannover eine neue Data-Warehouse-Architektur für ein Standardprodukt, das als Analyse-Komponente für die ERP-Verlagslösung des GRZ zum Einsatz kommt. Heterogene Kundenanforderungen, Customizing der ERP-Komponenten sowie ein gefoderter hoher Grad an Flexibilität und kundenindividueller Ausgestaltung spiegeln sich in einer Hub-and-Spoke-Architektur mit einem als Data Vault modellierten Core Warehouse und mehrdimensionalen Data Marts wider.
-
Data (Vault) Modeling and Deep Learning @ #XP19

Model driven decision making
During #XP19 you’ll be able to take part in our (Matze and myself) deep dive session about Model driven decision making: Data (Vault) Modeling and Deep Learning. It has been designed to give you a (very) short hands-on and practical guidance.
What is this 15 minute deep dive session about at #XP19?
-
Data Model Scorecard
Objective review and data quality goals of data models
Did you ever ask yourself which score your data model would achieve? Could you imagine 90%, 95% or even 100% across 10 categories of objective criteria?
No?
Yes?Either way, if you answered with “no” or “yes”, recommend using something to test the quality of your data model(s). For years there have been methods to test and ensure quality in software development, like ISTQB, IEEE, RUP, ITIL, COBIT and many more. In data warehouse projects I observed test methods testing everything: loading processes (ETL), data quality, organizational processes, security, …
But data models? Never! But why? -
Data Modeling Master Class
Kompetenz in der Datenmodellierung
Warum geben wir jedes Jahr Millionen Euro und Tausende Stunden für die Entwicklung von Lösungen aus, die nicht funktionieren?
Die mangelhafte Erfassung und Formulierung von Geschäftsanforderungen führt zu einer enormen Ressourcenverschwendung. Datenmodelle verhindern diese Vergeudung von Zeit und Geld, indem sie Geschäftsterminologie und -anforderungen in präziser Form und auf verschiedenen Detailebenen erfassen und so eine flüssige Kommunikation zwischen Unternehmen und IT sicherstellen.
Absolvieren Sie die Data Modeling Master Class, um Kompetenz in der Datenmodellierung zu erlangen. Die Data Modeling Master Class ist das Training zum Thema Datenmodellierung und wird mehrmals im Jahr öffentlich oder als spezielles virtuelles Training nur für Ihr Team angeboten.
Inhalte
Diese Data Modeling Master Class ist ein kompletter Datenmodellierungskurs, der über fünf Module hinweg praktische Techniken zur Erstellung konzeptioneller, logischer und physischer relationaler und dimensionaler sowie NoSQL-Datenmodelle vermittelt.
Nachdem Sie die verschiedenen Arten und die einzelnen Schritte der Anforderungserfassung und -modellierung kennengelernt haben, wenden Sie einen Best-Practice-Ansatz zur Erstellung und Validierung von Datenmodellen mithilfe der Data Model Scorecard® an. Sie verstehen nicht nur, wie man ein Datenmodell erstellt, sondern vor allem, wie man ein Datenmodell optimal gestaltet.
Diese Data Modeling Master Class umfasst drei Teile mit über 30 Übungen und 20 Stunden Unterricht:
Grundlagen
Nach Abschluss von Teil 1 sind Sie in der Lage, die Vorteile der Datenmodellierung zu erläutern, die fünf Vorgaben für die Erstellung eines Datenmodells anzuwenden und die einzelnen Datenmodellierungskomponenten (Entitäten, Attribute, Repräsentanten, Beziehungen, Subtypisierung, Schlüssel, Hierarchien und Netzwerke) richtig zu verwenden.
Schema
Am Ende von Teil 2 beherrschen Sie die Erstellung konzeptioneller, logischer und physischer relationaler und dimensionaler Datenmodelle. Sie sind außerdem in der Lage, NoSQL-Datenmodelle in Bezug auf die Modellierungsstruktur und den Ansatz von traditionellen Modellen zu unterscheiden.
Scorecard
Mit Abschluss von Teil 3 können Sie anhand der zehn Kategorien der Data Model Scorecard® Best Practices für Datenmodelle anwenden. Diese Kategorien sind Korrektheit, Vollständigkeit, Schema, Struktur, Abstraktion, Standards, Lesbarkeit, Definitionen, Konsistenz und Daten.
Nach Abschluss der Data Modeling Master Class wissen Sie nicht nur, wie man ein Datenmodell erstellt, sondern auch, wie man ein Datenmodell wirklich gut erstellt. Mit Hilfe der Data Model Scorecard® können Sie in Ihr Datenmodell unterstützende und ergänzende Funktionen einbauen und die Qualität eines jeden Datenmodells bewerten.
Fallstudien und die Übungen vertiefen den Stoff und ermöglichen es Ihnen, das Gelernte in Ihren aktuellen Projekten anzuwenden.
Die 10 wichtigsten Lernziele
- Sie können die Komponenten der Datenmodellierung erklären und sie in Ihren Projekten anhand von Fragen identifizieren.
- Sie können ein Datenmodell beliebiger Größe und Komplexität mit der gleichen Sicherheit lesen wie ein Buch.
- Sie können jedes Datenmodell mit Hilfe von wichtigen "Einstellungen" (Umfang, Abstraktion, Zeitrahmen, Funktion und Format) sowie mit der Data Model Scorecard® validieren.
- Wenden Sie Techniken zur Anforderungserhebung an, einschließlich Befragung, Artefaktanalyse, Prototyping und Arbeitsplatzbeobachtung
- Sie erstellen relationale und dimensionale, konzeptionelle und logische Datenmodelle und kennen die Kompromisse auf der physischen Seite sowohl für RDBMS- als auch für NoSQL-Lösungen
- Üben Sie das Aufspüren von Problemen der strukturellen Robustheit und der Verletzung von Richtlinien
- Sie können erkennen, wann eine Abstraktion sinnvoll ist und wo Muster und Branchendatenmodelle uns einen großen Nutzen bringen können.
- Die Verwendung einer Reihe von Vorlagen für die Erfassung und Validierung von Anforderungen und für die Erstellung von Datenprofilen
- Bewertung von Definitionen auf Klarheit, Vollständigkeit und Richtigkeit
- Verwendung von Data Vault und eines Unternehmensdatenmodells für eine erfolgreiche Enterprise-Architektur
Muss Vorwissen vorhanden sein?
Dieses Training erfordert keine Vorkenntnisse im Bereich der Datenmodellierung und ist daher an keine bestimmten Voraussetzungen gebunden. Dieses Training richtet sich an alle, die einen oder mehrere der folgenden Begriffe in ihrer Berufsbezeichnung haben: Daten, Analyst, Architekt, Entwickler, Datenbank und Modellierer.
Alle aktuellen Termine zur Data Modeling Master Class finden Sie in unserer Academy. Dieses Training wird von uns in deutscher Sprache unterrichtet.
Dieses Training wird von uns in deutscher Sprache unterrichtet. -
Data Modeling Master Class
Competence in data modeling
Why do we spend millions of euros and thousands of hours every year developing solutions that don't work?
Poor capture and formulation of business requirements leads to a huge waste of resources. Data models prevent this waste of time and money by capturing business terminology and requirements in precise form and at multiple levels of detail, ensuring fluid communication between business and IT.
Complete the Data Modeling Master Class to gain competency in data modeling. The Data Modeling Master Class is the training on data modeling and is offered several times a year to the public or as a special virtual training just for your team.
This training requires no prior knowledge of data modeling and is therefore not tied to any specific prerequisites.
Topics
This training is being taught in German.
This Master Class is a complete data modeling course, containing five modules of practical techniques for producing conceptual, logical, and physical relational and dimensional and NoSQL data models.
After learning the styles and steps in capturing and modeling requirements, you will apply a best practices approach to building and validating data models through the Data Model Scorecard®. You will know not just how to build a data model, but how to build a data model well.
This Data Modeling Master Class includes three parts with over 30 exercises and 20 hours of instruction:
Basics
After completing Part 1, you will be able to explain the benefits of data modeling, apply the five specifications for creating a data model, and properly use each of the data modeling components (entities, attributes, representatives, relationships, subtyping, keys, hierarchies, and networks).
Schema
By the end of Part 2, you will be proficient in creating conceptual, logical, and physical relational and dimensional data models. You will also be able to distinguish NoSQL data models from traditional models in terms of modeling structure and approach.
Scorecard
With the completion of Part 3, you will be able to apply best practices for data models using the ten categories of the Data Model Scorecard®. These categories are correctness, completeness, schema, structure, abstraction, standards, readability, definitions, consistency, and data.
After completing the Data Modeling Master Class, you will not only know how to create a data model, but also how to create a data model really well. Using the Data Model Scorecard®, you will be able to build supporting and complementary features into your data model and evaluate the quality of any data model.
Case studies and the exercises reinforce the material and allow you to apply what you have learned to your current projects.
Top 10 Learning Objectives
- Explain data modeling components and identify them on your projects by following a question-driven approach
- Demonstrate reading a data model of any size and complexity with the same confidence as reading a book
- Validate any data model with key "settings" (scope, abstraction, timeframe, function, and format) as well as through the Data Model Scorecard®
- Apply requirements elicitation techniques including interviewing, artifact analysis, prototyping, and job shadowing
- Build relational and dimensional conceptual and logical data models, and know the tradeoffs on the physical side for both RDBMS and NoSQL solutions
- Practice finding structural soundness issues and standards violations
- Recognize when to use abstraction and where patterns and industry data models can give us a great head start
- Use a series of templates for capturing and validating requirements, and for data profiling
- Evaluate definitions for clarity, completeness, and correctness
- Leverage the Data Vault and enterprise data model for a successful enterprise architecture
Prerequisites
This course assumes no prior data modeling knowledge and, therefore, there are no prerequisites. This course is designed for anyone with one or more of these terms in their job title: "data", "analyst", "architect", "developer", "database", and "modeler".
-
Data Modeling Zone 17
After all, I am very happy to be a speaker at this year's Data Modeling Zone in Düsseldorf. Again, like at the Global Data Summit, I'm talking about one of my favorite topics: Temporal data in the data warehouse, especially in connection with data vault and dimensional modeling.
-
Data Modeling Zone Europe 2015

Do you want to learn something about data modelling with Steve Hoberman? You want to explore new methods like Data Vault 2.0, Anchor Modeling, Data Design, DMBOK and many more? E.g. a keynote where Dan Linstedt, Lars Rönnbäck and Hans Hultgren talks together, and another one with Bill Inmon?
-
Data Vault - Datenmodellierung noch notwendig?
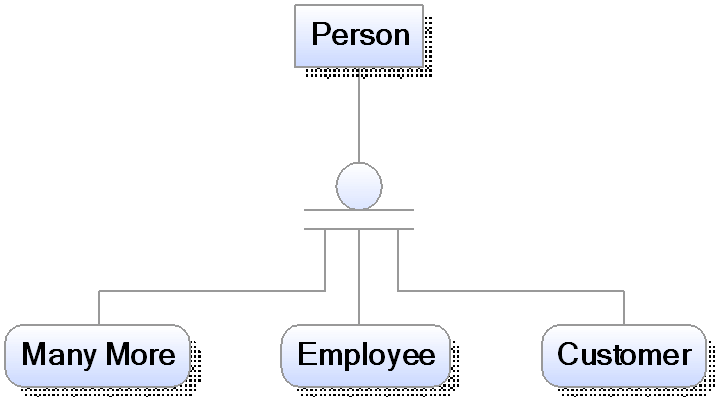
Wie bereits in meinem Blogpost Modellierung oder Business Rule beschrieben ist es notwendig sich bei der Datenmodellierung über Geschäftsobjekte, die Wertschöpfungskette, fachliche Details und die Methodik des Modellierens einige Gedanken zu machen.
Oder doch nicht? Kann ich mit Data Vault einfach loslegen? Schließlich ist Data Vault auf den ersten Blick ganz einfach. Drei Objekte: HUBs, LINKs und SAT(elliten), einem einfachen Vorgehensmodell und ein paar wenige Regeln. Brauche ich für Data Vault noch die Datenmodellierung?
-
Data Vault Link Satellites: Use, decision support and examples

And there it was again, the lively discussion about the use of a Data Vault Link Satellite. The argumentation, whether yes or no, went round in circles.