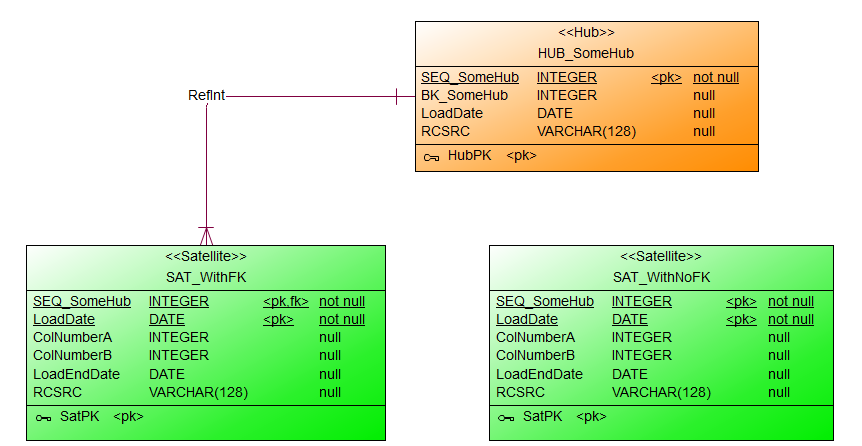
Immer wieder kommt in Projekten die Frage auf, besser gesagt die Diskussion, ob Constraints in der Datenbank physisch sinnvoll sind oder nicht. Meist gibt es Vorgaben von DBAs oder durchsetzungsstarken ETLern, die eine generelle Abneigung gegen Constraints zu haben scheinen, dass Constraints nicht erwünscht sind. OK, diese Woche wurde mir wieder das Gegenteil bewiesen. Doch wie heißt es so schön: Ausnahmen ...
Auf dem #WWDVC und im Advanced Data Vault 2.0 Boot Camp haben wir ebenfalls über dieses Phänomen gesprochen. Das scheint weltweit zu existieren. Dazu hat kurz nach dem #WWDVC auch Kent Graziano einen Blogpost verfasst. Auf LinkedIn gab es dazu einige Kommentare.
Gut, wie argumentiert man am besten, bzw. was sind eigentlich die Vor- und Nachteile Constraints zu verwenden?

Anreise
Die Anreise zur Schulung mit KLM verlief ohne Probleme. Von Frankfurt nach Montreal, mit einem kurzen Stopp in Amsterdam und dann entspannt mit dem Auto über verschneite Landschaften nach St. Albans, VT, USA.
Auf dem Flug nach Amsterdam gab es viel Spaß im Flieger, da einer der Supervisors an Board seinen letzten Flug auf dieser Maschine hatte und sein Team ihn gebührend verabschiedete.
Das 1. Deutschsprachige Data Vault User Group (#DDVUG) Treffen findet auf der TDWI Konferenz 2014 in München statt. Dan Linstedt wird als Ehrengast extra aus St. Albans zu unserem Treffen kommen und einen Vortrag über Data Vault halten.
Darüber hinaus wird es viele anregende Vorträge und Diskussionen aus der Praxis geben. Es soll schließlich der Austausch zwischen allen Teilnehmern gefördert, das Fachsimpeln und Netzwerken im Vordergrund stehen.

Es ist eine Weile her seit ihr von mir etwas gehört habt. Entschuldigung.
Dafür geht es gleich mit etwas Großem weiter. Rückblickend wird es sich zeigen, ob hier ein historisches Ereignis in der Datenmodellierungsszene stattfindet: das erste weltweite Treffen (20.3.14 - 22.3.14) von Data Vault Interessierten in der Heimatstatt von Daniel Linstedt, in St. Albans, USA.
Page 7 of 9