KISS –
K – Keep (Data Vault)
I – It (ETL in your Data Warehouse)
S – Small (lightweight processes aka short and easy SQL)
S – and simple (easy Inserts and Updates)
Oder in einem ganzen Satz
Keep your Data Vault, especially your ETL/ELT in your Data Warehouse as small and simple as possible. Small means short, easy and lightweight SQL processes like Inserts and Updates!
- HUB – Load ELT processes – Insert only
- LINK – Load ELT processes – Insert only
- SAT(elite) – Load ELT process – Insert (and Update) only
Mehr als einfaches DML (Insert / Update) braucht es zur Beladung eines Data Vault nicht. Die Prozesse begrenzen sich auf wenige Statements, die wenige Zeilen Code enthalten.
Einwand von X: Aber was ist mit Fehlererkennung, Nachladen usw.? Bisher habe ich all das immer in meine (genialen, großen, die nur ich verstehe) Prozesse eingebaut!
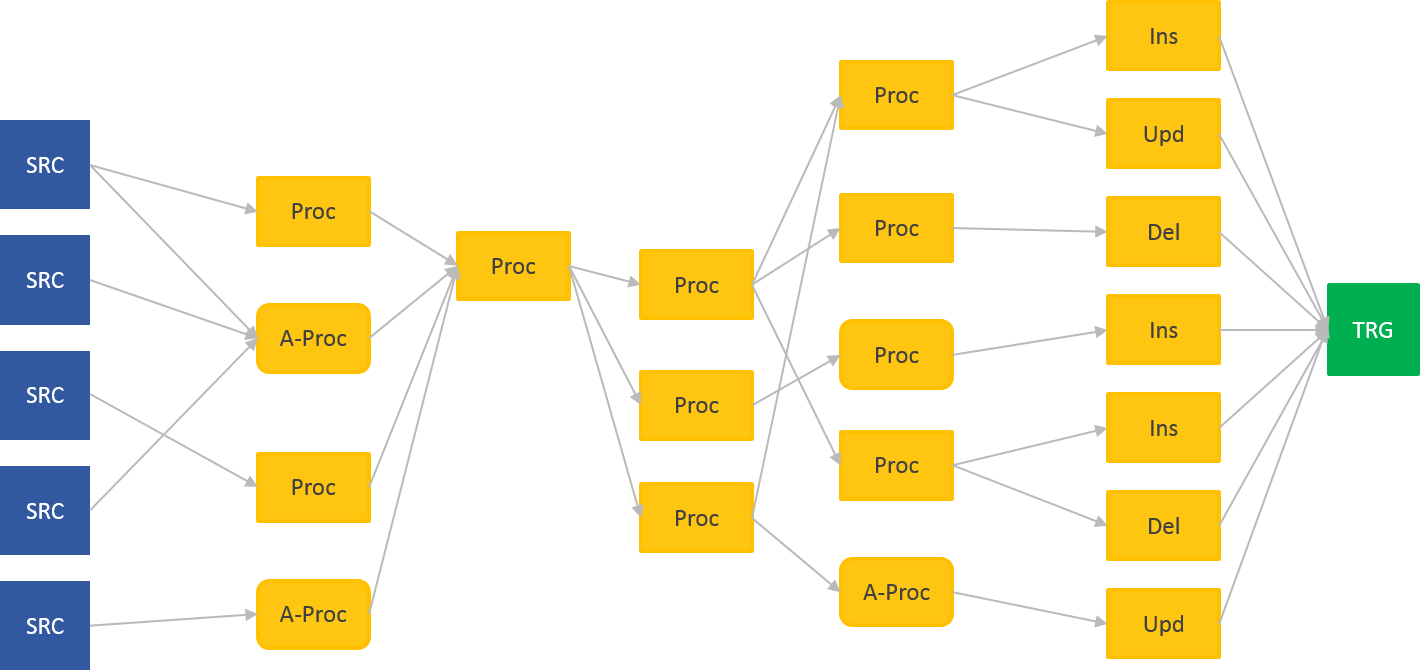
Jep, richtig. Jedoch zur richtigen Zeit am richtigen Platz:
- Abhängig vom Projektvorgehen: Baut das Team das Data Warehouse mit agilen Methoden oder nach dem Wasserfallprinzip.
- Abhängig von der Ursache: Fehler, Schnittstelle, externe Einflüsse und vieles mehr.
In einem agilen Vorgehen, siehe auch die Zwölf Prinzipien Agiler Softwareentwicklung, entwickelt das Team nur das, was zum Erreichen der Ziele in einer Timebox notwendig ist.
Extrem ausgedrückt: Fehlerkorrekturprozesse werden erst entwickelt, wenn diese Fehler aufgetreten sind. Funktionierende Fehlerprozesse, die auf „Vorrat“ entwickelt wurden, liefern ohne Fehler keinen Mehrwert und laufen dem Prinzip „Unsere höchste Priorität ist es, den Kunden durch frühe und kontinuierliche Auslieferung wertvoller Software zufrieden zu stellen“ zuwider. Des Weiteren sind Fehlerkorrektur-Prozesse eigenständige Prozesse und nicht Teil des eigentliche Data Vault Prozesses. Sie sind Teil der gesamten Prozesskette.
Nicht in die oben genannten Data Vault Prozesse gehören z.B. auch schnittstellenspezifische Anforderungen an die Prozesse. Daten einer XML-Schnittstelle sind anders vorzubereiten als ein Fixed-Length-Flat-File. Oder das zeitliche Zusammenfassen von eigentlich eigenständigen Ladezyklen. Das kann bei der Anlieferung von Messages aus einer Queue an das Data Warehouse sinnvoll sein, bedeutet aber Aufwand in der Aufbereitung der Daten für die Data Vault Prozesse.
Warum dann nicht in die Data Vault Prozesse einbauen?
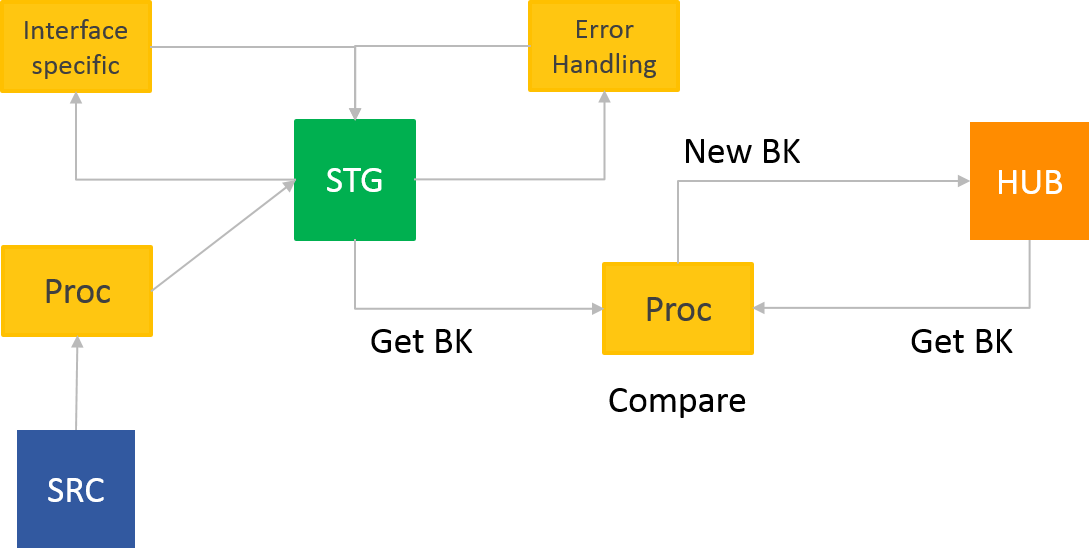
Weil es schnittstellenspezifische Anpassungen sind. Bei 100 Schnittstellen zum Data Warehouse ist es z.B. nur für fünf davon notwendig diese Anpassung durchzuführen. Bei den restlichen 95 würde dadurch der Data Vault Prozess unnötig belastet.
Die beiden beschriebenen Fälle sind Teil eines gesamten Ladeprozesses in ein Data Warehouse, aber nicht Teil der Data Vault Ladeprozesse!
Divide and Conquer
Schlanke, durch Metadaten erzeugte Ladeprozesse sind sehr effizient, leicht zu pflegen und zu testen. Das ist die Basis zur Automatisierung im Data Warehouse.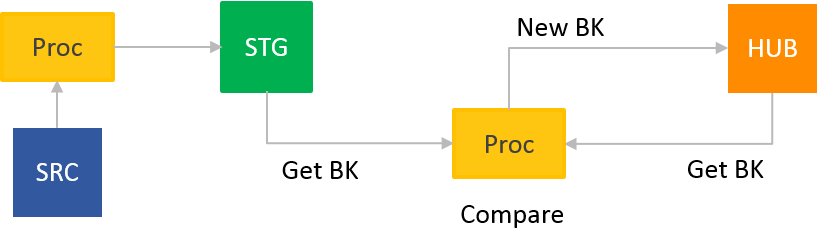
Also, macht euch das Leben einfach indem ihr immer an KISS denkt!
So long
Euer Dirk