Welche Zeit nehme ich für die Timelines in den Data Vault Entitäten? In meinen Projekten stellt sich immer wieder diese Frage. Dokumentiert das LoadDate im HUB, im LINK und im SAT den Load Date TimeStamp (LDTS) nach Dan Linstedt, oder doch die Transaction Time zu der Daten im Quellsystems entstanden sind? Oder besser die Extraktionszeit? Oder die Transaktionszeit der Datenbank1) zu der die Datenbank die Datensätze in die Tabellen speichert? Nicht einfach zu beantworten, oder?
Eine aktualisierte Version dieses Artikels ist veröffentlich: Welcher Zeitstempel für eine Data Vault timeline?
An updated version of this article is published: How to choose a timestamp for a Data Vault timeline?
Lasst uns mal diese Fragestellung aus Sicht der Fachabteilung betrachten. Was möchte diese haben:
- Accuracy, when did I get my data: Konsistente, widerspruchsfreie Berichte, die jederzeit reproduzierbar sind. Wann waren die Daten im EDWH bekannt? Welche Daten passen zu welchen Daten (zeitliche Sicht) um ein einheitliches Bild meines Geschäfts zu zeigen?
- Consistency, according to source systems: Möglichst genau, präzise Informationen darüber, wann Daten in der Quelle entstanden sind, dafür keine konsistenten Reports. Es ist nicht zwingend notwendig, dass Berichte zu 100% reproduzierbar sind?
- Sind alle Systeme (Quellsysteme, Datenbanken, Anwendungen) mit der gleichen Zeit (z.B. über einen Zeitserver) synchronisiert? Gerade Anwendungen kümmern sich nicht immer liebevoll um die korrekte Zeit beim Speichern in die Datenbanken.
- Erhalte ich Informationen über die Zeitzonen in der Daten entstanden sind oder nur UTC?
- Werden Sommer- und Winterzeit berücksichtigt?
- Ist die (Creation) Transaction Time der Quelle in der Realität nicht eine (Last Changed) Transaction Time?
Generell sollte das (Modellierungs-) Team sich im Klaren darüber sein, ob man Zeiten, die nicht in der eigenen Datenbank erzeugt werden, trauen kann:
Diese Fragen zu beantworten, ist entscheidend für die Wahl der Zeit im Data Vault. Damit beeinflusst der oder die Entscheider maßgeblich, wie später Daten und Informationen in der Abfrageschicht erscheinen.
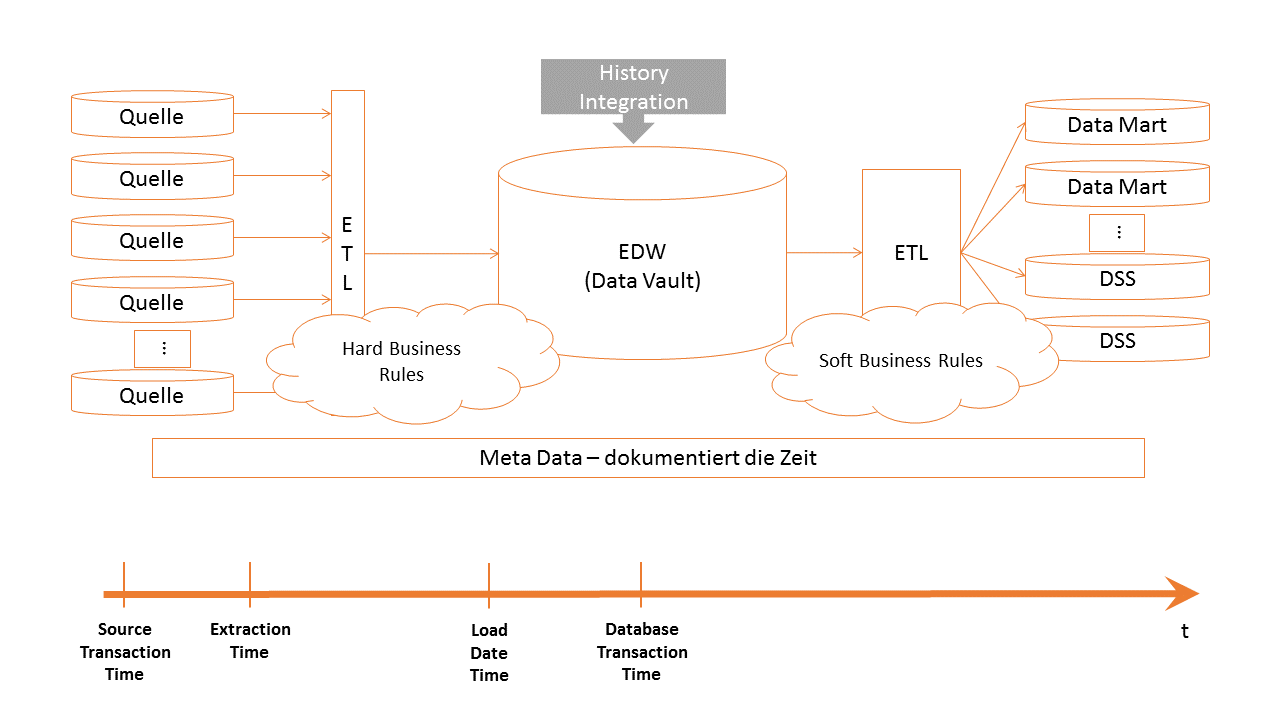 Darüber hinaus sollten, nach meiner Meinung, jeder Zeitpunkt, (z.B. Transaction Time (Source), Extraktionszeitpunkt, Load Cycle Date, Load Transaction Time usw.), die die Daten auf dem Weg in das EDWH passieren, die ETL-Prozesse in einem geeigneten Metadatenmodell speichern. Ein tolles Beispiel für ein Metadatenmodel (One (Metadata) Column To Rule Them All) hat Martijn auf seinem Blog beschrieben.
Darüber hinaus sollten, nach meiner Meinung, jeder Zeitpunkt, (z.B. Transaction Time (Source), Extraktionszeitpunkt, Load Cycle Date, Load Transaction Time usw.), die die Daten auf dem Weg in das EDWH passieren, die ETL-Prozesse in einem geeigneten Metadatenmodell speichern. Ein tolles Beispiel für ein Metadatenmodel (One (Metadata) Column To Rule Them All) hat Martijn auf seinem Blog beschrieben.
Ein durchdachtes Metadatenmodell ist in der Lage die Grenzen zwischen Accuracy und Consistency aufzuheben. Durch die Dokumentation der unterschiedlichen Zeiten im Metadatenmodell kann eine Abfrageschicht zwischen Accuracy und Consistency wechseln.
So long,
Euer Dirk
1) Zeitpunkt an dem die Daten in der Datenbank bekannt waren.